Customer service teams have one end goal—to satisfy and delight every customer that seeks assistance.
But can they actually inch closer to this goal when the ticket backlog runs in heaps?
To address this, organizations opt to hire more support agents. There’s a catch though: agents have to manually figure out what the ticket is all about. Hence, if the relevant fields—category, product type, etc.—are missing, it will eventually take a toll on the agent’s productivity.
If you are bearing the brunt of missing data in case fields, then you need to revisit your customer support strategy and pay heed to case classification; because for a case or ticket to be solved efficiently, it is critical to populating relevant information from the get-go. Let’s dive deeper.
What is Case Classification?
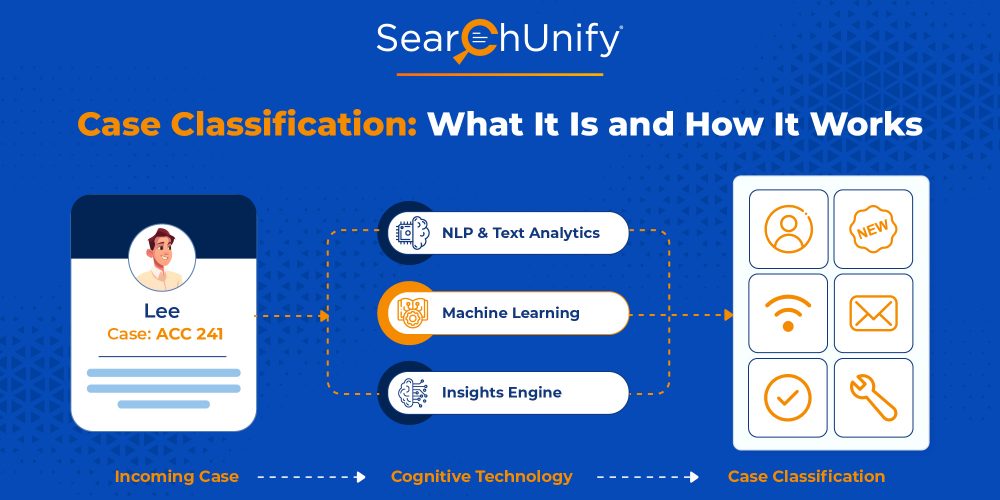
Case classification is a process of recognizing, understanding, and labeling incoming support tickets so they can be grouped with relevant predetermined categories. For example, you are evaluating tickets and you want to classify them into various sets of domain-specific fields. You could record field values like Product type, Expertise, Skill Sets, Categories and Subcategories, and so on. Based on these attributes, you could train data, and after that, whenever a new data set is recorded, case classification algorithms would tap into its predictive intelligence to populate picklists and checkbox fields. As a result, the new data set would automatically be classified into one of the categories.
Benefits of Case Classification
There are myriad benefits of case classification for both customers and agents in the customer service realm.
- Improved Agent Productivity: Since cases are automatically classified, agents have to spend less time scrolling, searching, and populating picklists for the right field values. Consequently, they get to spend more time understanding and resolving complex customer issues.
- Faster Resolutions: Since the context of the ticket is rightly populated and presented, agents can solve the data with a wider set of data points available.
- Consistent Data Quality: When cases are classified using the predictive model, data accuracy on cases improves manifold as the likelihood of committing human errors reduces.
The ultimate goal of any customer service center is to provide stellar experiences. When data quality improves, customers find resolutions to their problems quickly, and agents have ample time to understand their customers. Subsequently, the customer experience improves.
How Does Case Classification Work in the Customer Service Industry?
A support ticket has various components, including free text, the nature of the issue, the source of origin, etc. Based on that, machine learning algorithms identify different classes of historical data. Then, semantic embeddings are generated for each previous case that is fed to the training model with classes to predict. So, every time a new data set is entered, case classification algorithms recommend or populate certain fields based on the previous case data.
Leveraging KNN for case classification is a good idea as they provide better explainability of how a case is classified into a particular class. It also helps in the inference of various fields with a lack of relevant data, where other algorithms would have failed in order to improve both customer and agent experiences.
Want to Unravel the Mystery of SearchUnify’s Robust Case Classification?
There are a couple of classification algorithms in machine learning. Some of them include Logistic regression, K-Nearest Neighbors (K-NN), Decision trees, Artificial neural networks, and Naive Bayes. We, at SearchUnify, stick to K-Nearest Neighbors due to its simple implementation and immunity against noisy training data. Although limited training data is required in this approach, even if it’s humongous, this method is quite efficient in customer case management.














