
A steady stream of support tickets is the norm for many organizations. But from troubleshooting technical glitches to addressing product inquiries, the influx of tickets can quickly become overwhelming for customer support teams.
To make matters worse, the incoming cases are of varying types and priorities, making it crucial to segregate them for ensuring efficient resolutions.
This is where the concept of case clustering comes into play. Read on to explore its significance and how it empowers organizations to transform their support operations into efficient and customer-centric processes.
What Is Case Clustering?
Case clustering is a technique that plays a crucial role in optimizing the efficiency of support agents by grouping similar customer concerns into the same segments. This allows support teams to gain valuable insights, improve response times, and effectively address customer concerns.
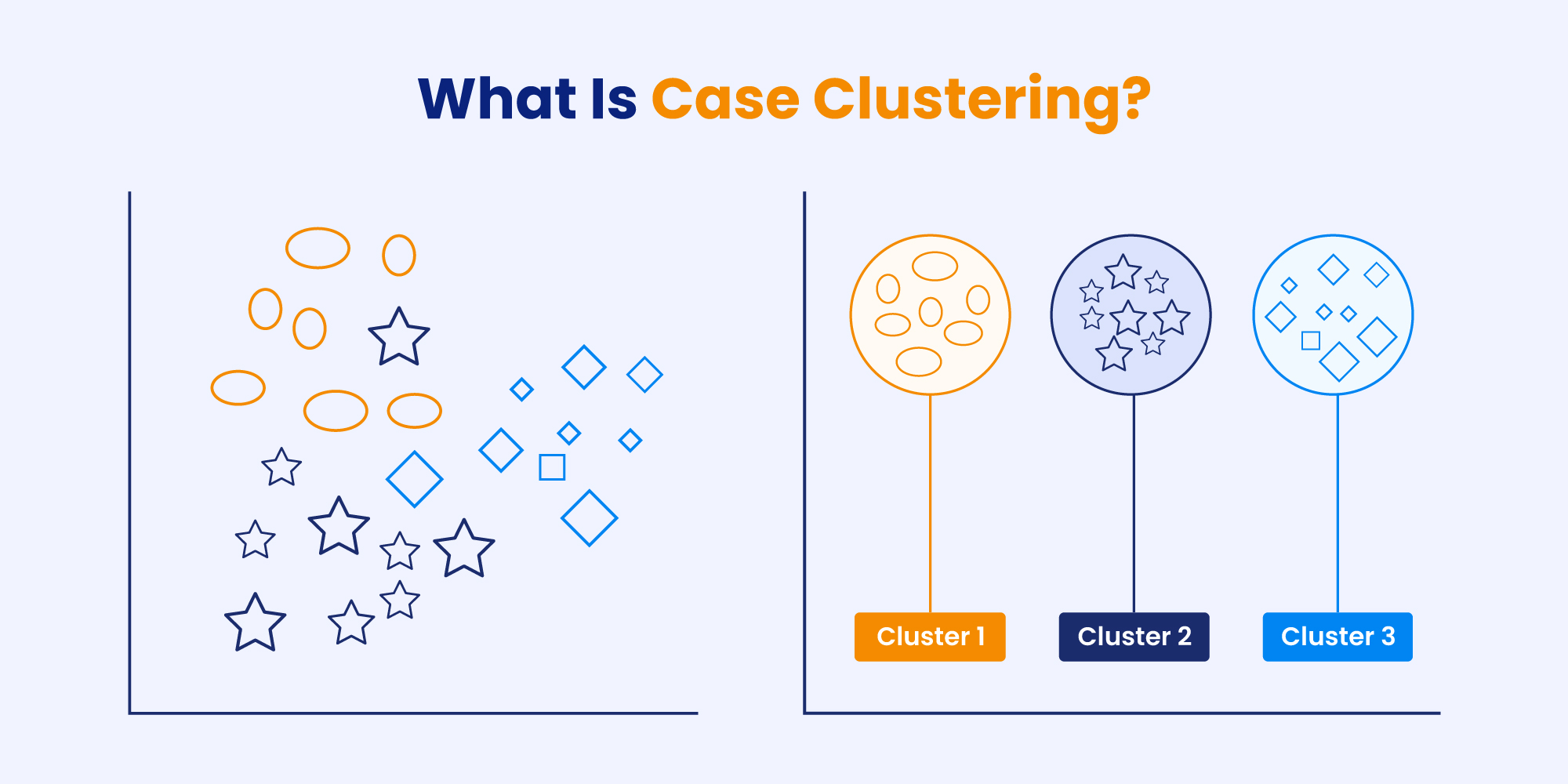
It can be further divided into a few categories, let’s check them out.
Types of Clustering
- Hard Clustering
This refers to assigning data points exclusively to either one or the other cluster. For instance, segmenting four customers into four groups would mean that each group is assigned exactly to one customer. -
Soft Clustering
As opposed to hard clustering, no data points are strictly assigned to one cluster, but multiple ones are based on their similarities to each cluster. It is also referred to as “fuzzy clustering” because of the blurry boundaries between clusters.Now the question arises, how exactly are these clusters formed? This is done with the help of algorithms known as cluster models that group together similar cases based on their attributes. Let’s take a look at them in detail.
Types of Cluster Models
Cluster models aim to create clusters by identifying patterns in data. The most common types are:
- Hierarchical Models: Builds a hierarchy of clusters by individually dividing datasets into smaller subgroups until each subgroup holds only one data point.
- Centroid-based Models: Models like K-Means clustering, which represents each cluster with a single mean vector.
- Connectivity Models: Represents each cluster with a single mean vector.
- Distribution Models: Clusters are modeled using statistical distributions.
- Density Models: Models like DBSCAN and OPTICS define clustering as a connected dense region in data space.
- Group Models: These models don’t provide refined results and only offer grouping information.
- Graph-based Models: A subset of nodes in the graph connects every two nodes in the subset can be considered as a prototypical form of cluster.
- Neural Models: Self-organizing maps are one of the most commonly known unsupervised neural networks.
Note: Clustering indicates the distance between two points and two clusters, which cannot be negative. Mentioned below are a few common measures of distance that algorithms used for clustering.
Measures of Distance
- Euclidean Distance: It is the default distance measure used in machine learning, as it is easy to understand and computationally efficient. It is calculated as the square root of the sum of the squared differences between the corresponding coordinates of the two points.
- Manhattan Distance: It is calculated as the sum of the absolute differences between the corresponding coordinates of the two points.
- Minkowski Distance: In-dimensional space, the distance between two points is called the Minkowski distance. It is a generalization of the Euclidean and Manhattan distance that if the value of p is 2, it becomes Euclidean distance and if the value of p is 1, it becomes Manhattan distance.
Optimizing Business Processes with Case Clustering
- Enhanced Customer Segmentation: By segmenting the customers based on their demographic, behaviors, or purchase histories, businesses can identify different needs and preferences. This can help in targeted marketing, product development, and strategic decision-making.
- Organized KBs: Case clustering enables grouping similar documents and knowledge bases (KBs) based on their topic relevance. This proves invaluable for organizations dealing with large volumes of data, ensuring quick and accurate information retrieval and facilitating seamless knowledge management.
- Optimized Customer Retention: Clustering customer interactions, such as support tickets, chat logs, and social media messages, allows companies to identify recurring issues and themes that affect their customers. This valuable information enables improvements in products and services, fostering higher customer satisfaction, and strengthening customer loyalty.
- Accelerated Resolutions: Organizing data into clusters enables support agents to efficiently handle similar cases, resulting in faster resolutions. Additionally, quick access to relevant KBs within the clusters further streamlines the support process, enhancing customer satisfaction through prompt and effective assistance.
How SearchUnify Leverages Case Clustering to Enhance Customer Experience and Engagement
Discover the multitude of benefits that arise from implementing case clustering techniques with SearchUnify, a unified cognitive platform, in your support ecosystem:
- Improved Case Deflection Rates: By identifying common clusters in escalated cases, SearchUnify helps you uncover repetitive customer issues, allowing you to proactively update your knowledge bases (KBs) and deflect cases before they occur, leading to improved customer satisfaction.
- Targeted Focus Areas: Out of 1000 cases, 10 clusters are formed, four of which can be the top clusters that hold the most repetitive cases. SearchUnify identifies these clusters, making it easier to pinpoint the areas that require immediate attention, ensuring focused efforts on resolving critical customer concerns.
- Informed Product Roadmap: Uncover valuable insights into customer needs by analyzing frequently searched topics and prominent clusters. These insights empower businesses to incorporate customer-centric features and improvements into their product roadmap, aligning their offerings with customer expectations.
- Amplified Content Findability: SearchUnify’s robust enterprise search solutions prioritize content findability. By automatically tagging KBs based on clusters, users can effortlessly navigate and access relevant information. Additionally, the platform analyzes user content consumption patterns to suggest additional content of interest, further enhancing engagement and knowledge discovery.
Revolutionize Your Case Clustering Capabilities with SearchUnify Today!
Embracing case clustering empowers businesses to rise above the support ticket chaos and transform their customer support into an exceptional experience. Game-changer platforms like SearchUnify can help. Discover how its case clustering capabilities can revolutionize your customer support efficiency, propelling your business toward greater success and customer satisfaction. Request a demo to know more.













