
Over the past few years, intelligent technologies like ML and AI have rapidly gained traction and revolutionized all walks of industries. But have you ever wondered what goes under the hood of these mighty forces that accelerate successful digital transformations and fuel business outcomes expeditiously?
Enter SearchUnify’s ML Workbench! The idea was whipped up to ensure the unified cognitive platform’s ML algorithms are no longer confined to a black box where you’re aware of the inputs and outputs but don’t know how they are determined.
But not anymore. At SearchUnify, we’re offering our users the tools to test the impact of our proprietary machine-learning algorithms. This means that an individual interested to understand the science behind deep learning algorithms need not go through extensive learning programs. I know what you are pondering next.
So, What Are We Bringing to the ML Playground?
For starters, the ML Workbench has been introduced for two features—Rich Snippets and Content Annotation. So, without further ado, let’s start with the fundamentals.
What Are Rich Snippets?
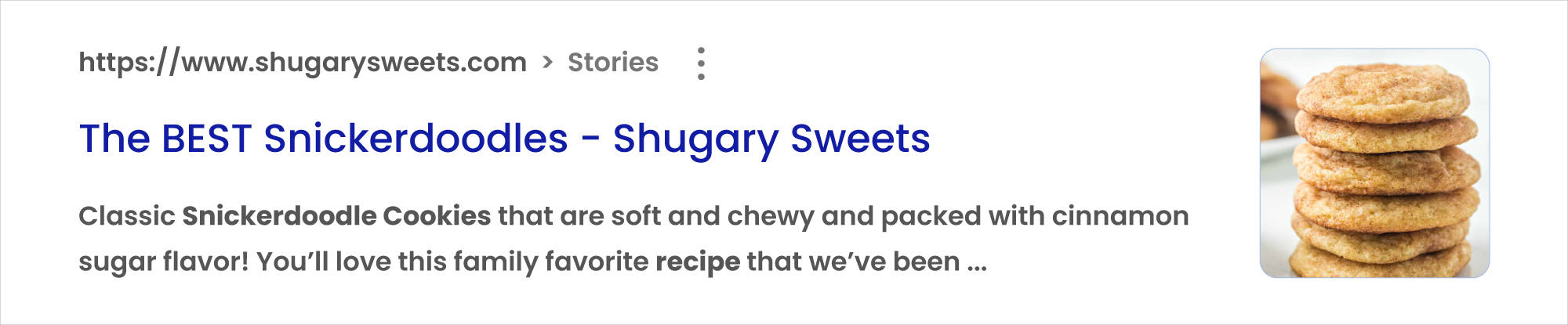
Rich snippets are visually appealing search results that display interactive and valuable information apart from the usual title, description, and URL. The additional information is extracted from structured data on the webpage’s HTML.
A typical google search result looks like this:
Whereas, a rich snippet looks like:
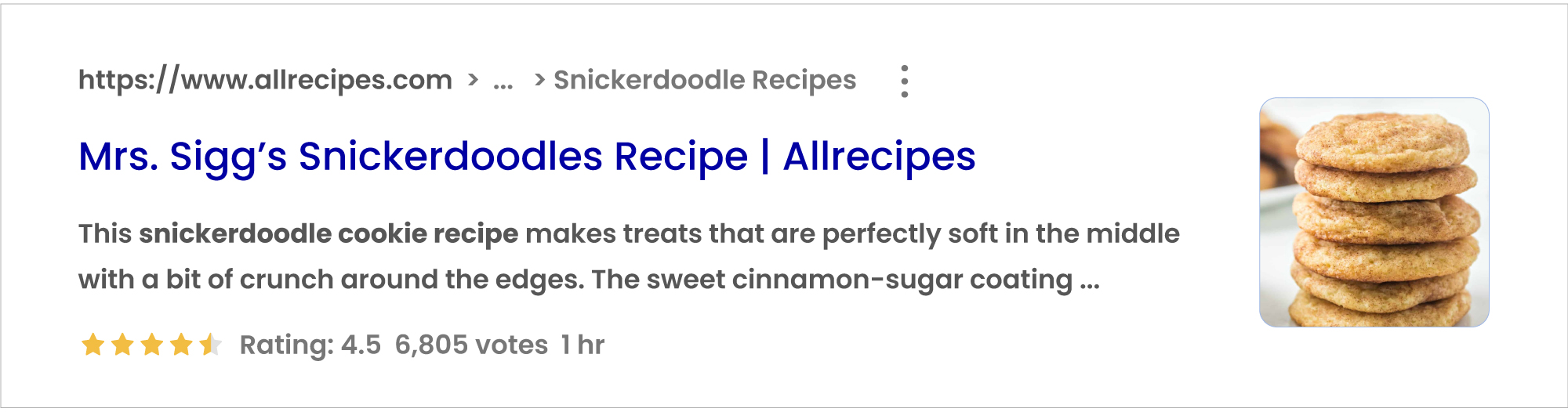
Information like page ratings, votes, duration, etc. draws attention and encourages more engagement. Some common types of rich snippets include reviews, recipes, and events.
ML Workbench – Rich Snippets Behind-the-Scenes
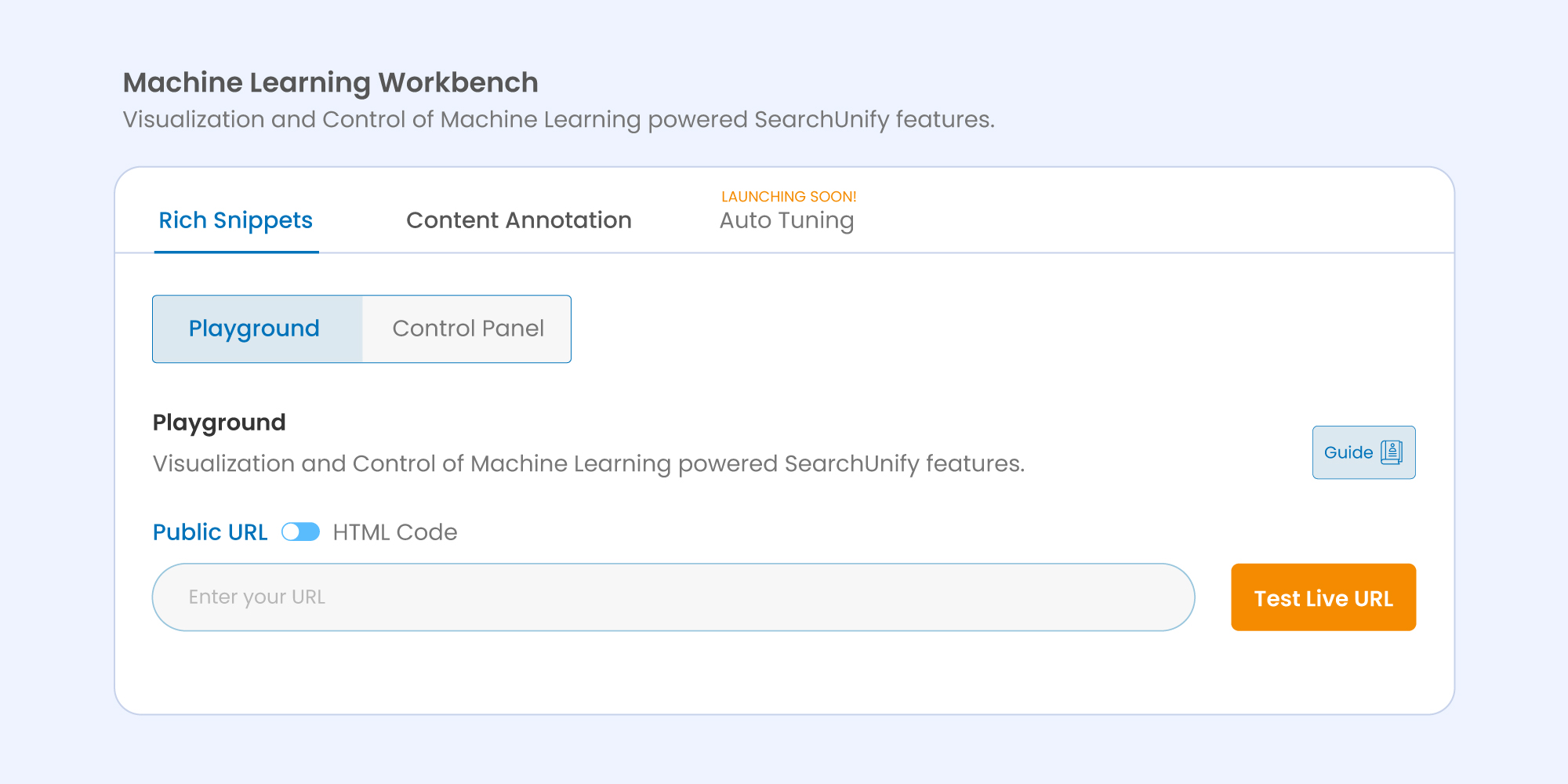
Coming back to comprehending the functioning, users now have the ability to test their publicly accessible pages and HTML codes (one at a time) to get a sneak peek of the rich results that will be generated out of the structured data on the page. Let’s understand this better with the help of an example.
This is how the workbench interface looks like at the backend:
Let’s generate rich snippets for a famous online recipe hub – Hebbar’s Kitchen.
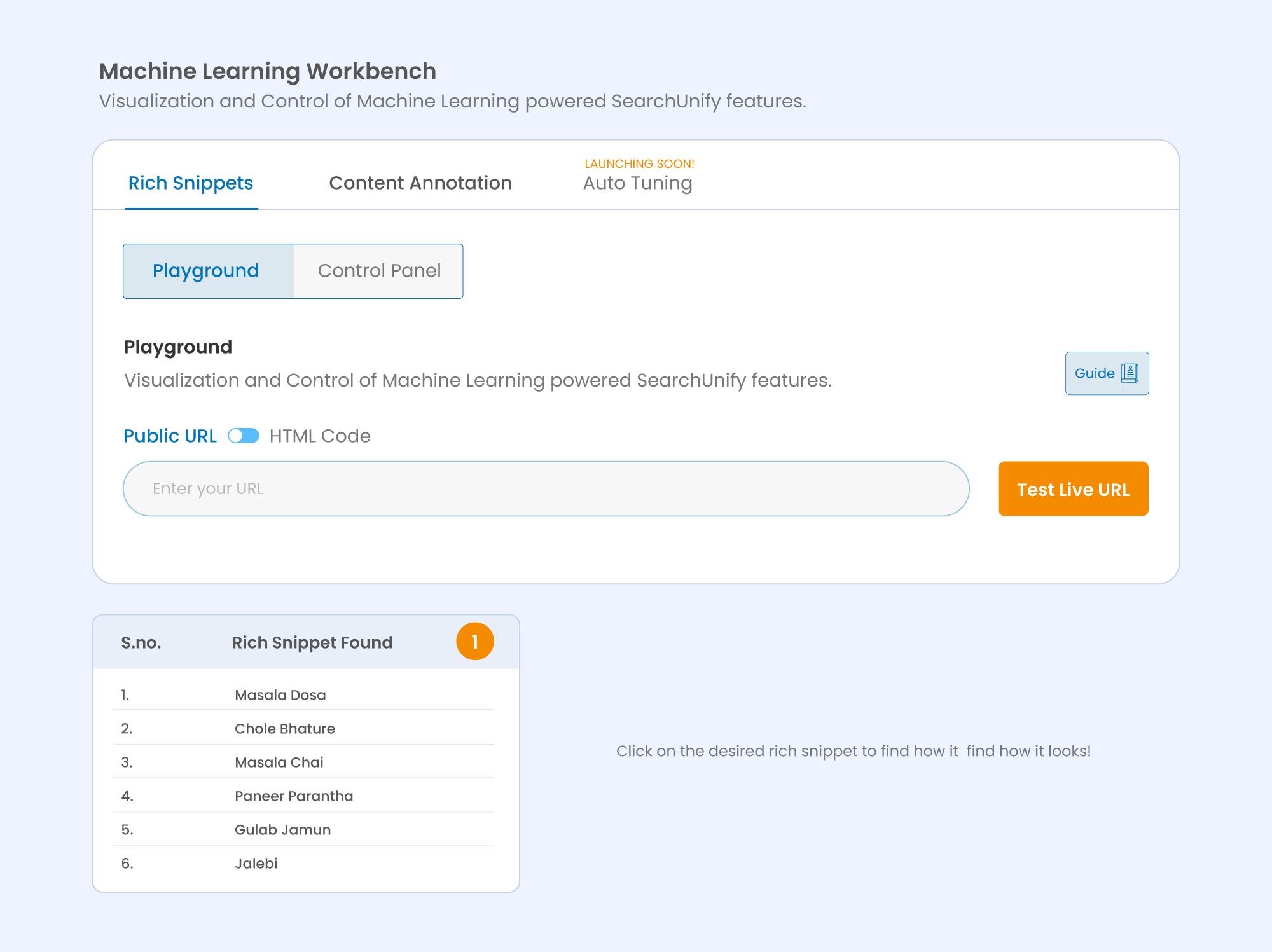
As you can see, a list of rich snippets appears for the entered URL. When you click on any of the listed snippets, it will open a preview displaying how the rich snippet looks on the search page. What’s more? On the right-hand side of the screen, users will also be able to view the list of keywords that contributed to the generation of this snippet.
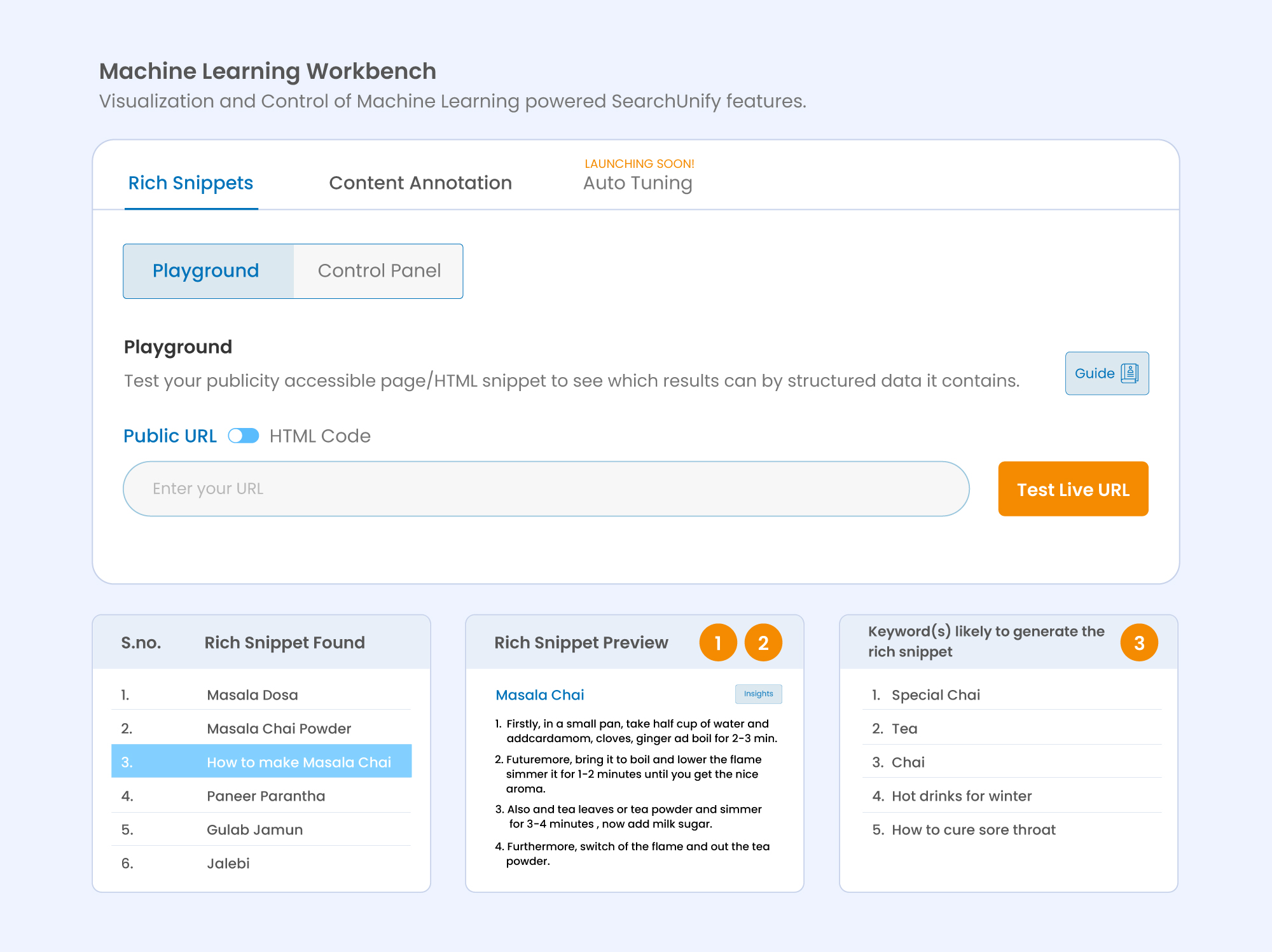
Next up, the Rich Snippet Preview has an Insights button. Clicking on it opens two new sections:
- Finding the Source of Rich Snippet: This section shows the part of the page that was highlighted (fetched live from URL) where we found the rich snippet.
- Corresponding HTML Element(s): Just like the name suggests this segment shows the HTML snippet for the same part of the page being displayed on the left.
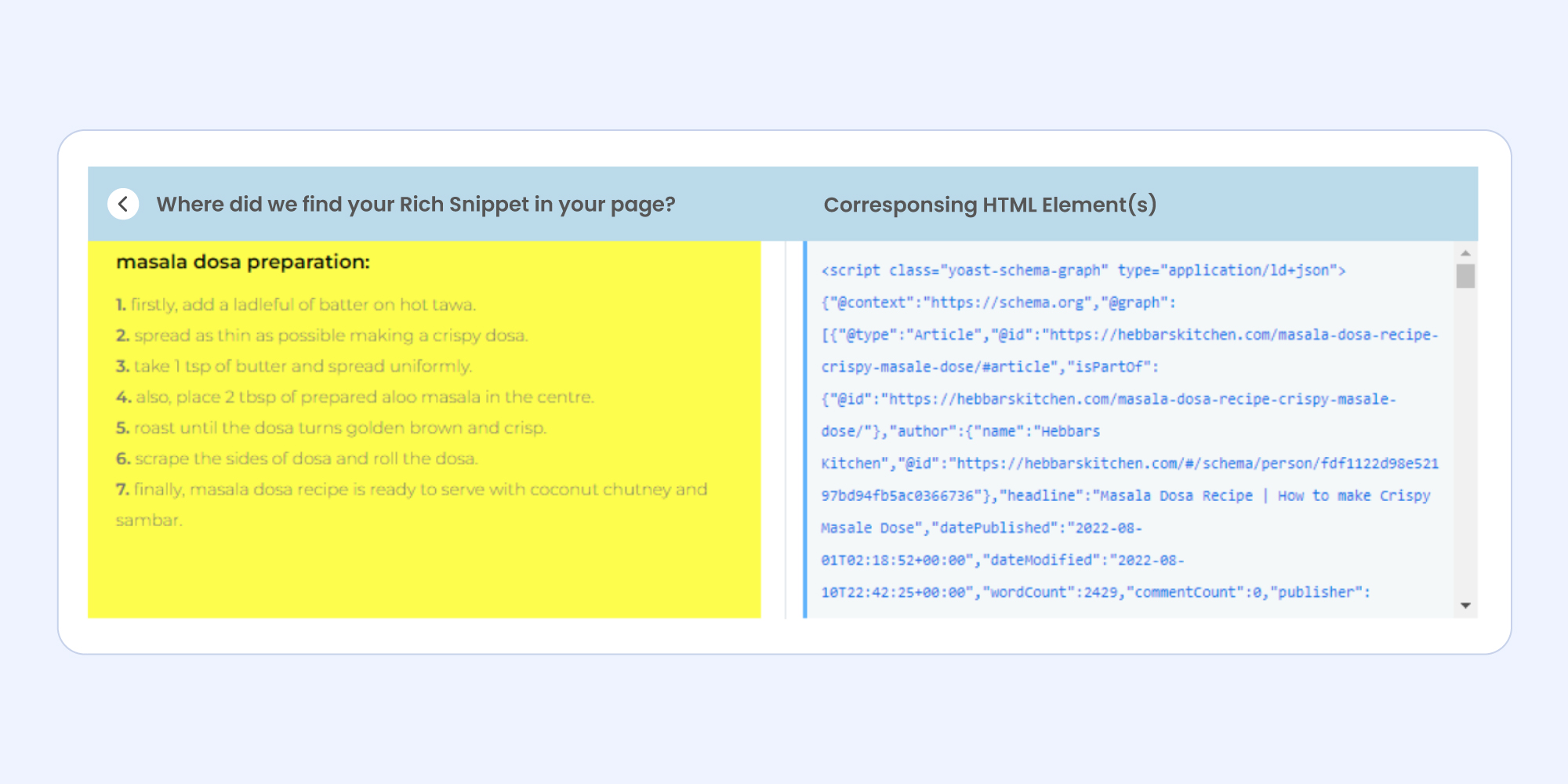
In order to test the HTML code, simply switch the toggle and follow the same steps to test your code.
While I do realize all the above illustrations take inspiration from food but good food makes everything better, doesn’t it?
What is Content Annotation?
Machines can’t process visual information the way humans do. For a computer to make decisions, it must be told what it’s interpreting by feeding it with ample context.
Content annotation can do that without breaking a sweat. It is the process of labeling data into predefined categories or formats like videos, images, and texts so that machines can comprehend them.
ML Workbench – Content Annotation Behind-the-Scenes
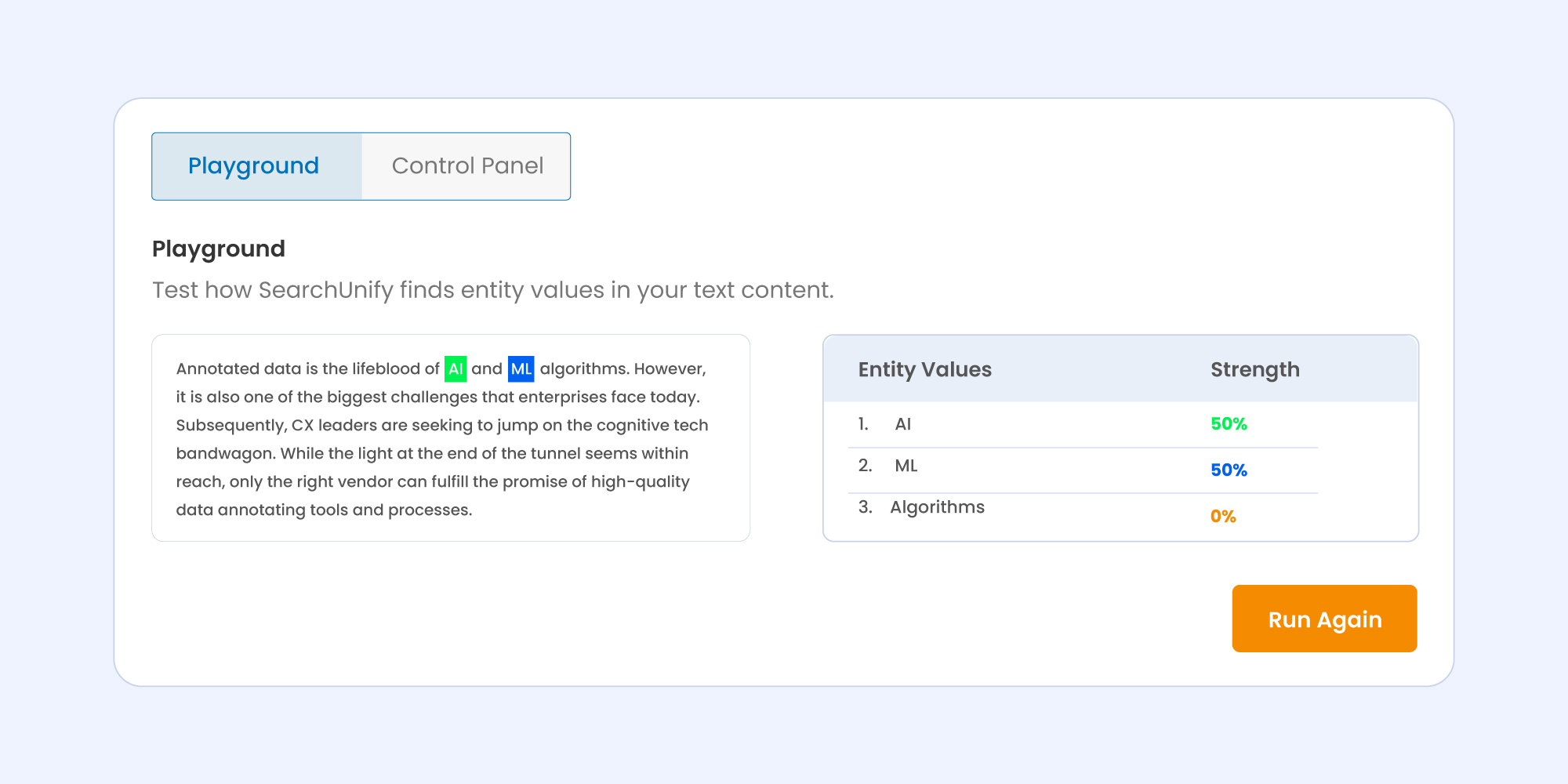
For content annotation, the playground allows you to test how SearchUnify finds entity values and their strength from the text content. Too long winding to understand? Let’s understand what goes under the hood with a coherent example.
To begin with, paste your text in the box on the left-hand side.
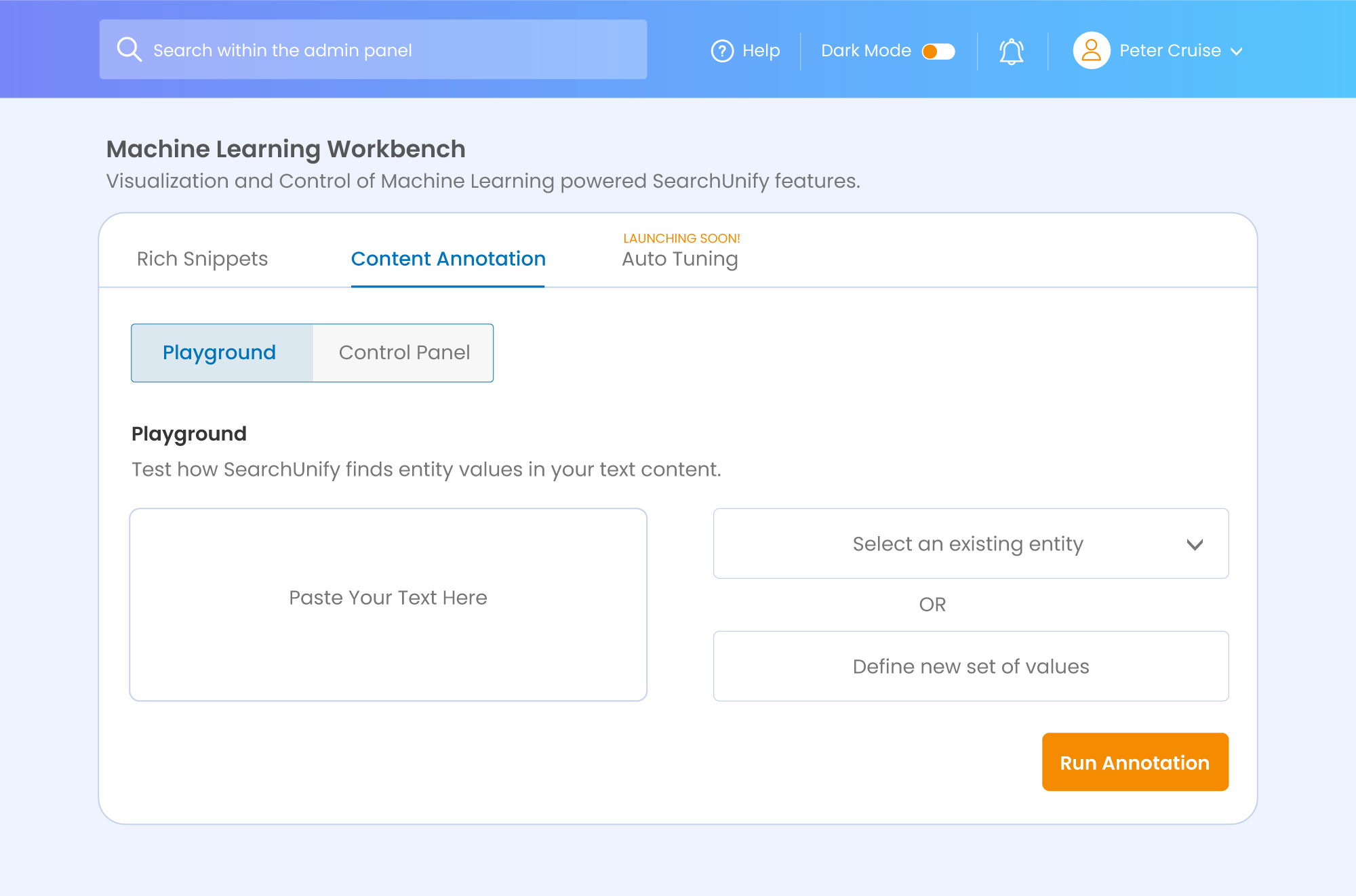
Then run annotation using either of the two options:
- Pre-defined Set of Taxonomy Entities: Choose an already existing entity added to the Taxonomy (NLP Manager).
- New Set of Values: Define a new value or a new entity.
Next up, I added a new entity (AI) and ran the annotation for the text. Thereafter, two sections appeared:
- The paragraph with highlighted entity values.
- An entity value list with its strengths in percentage.
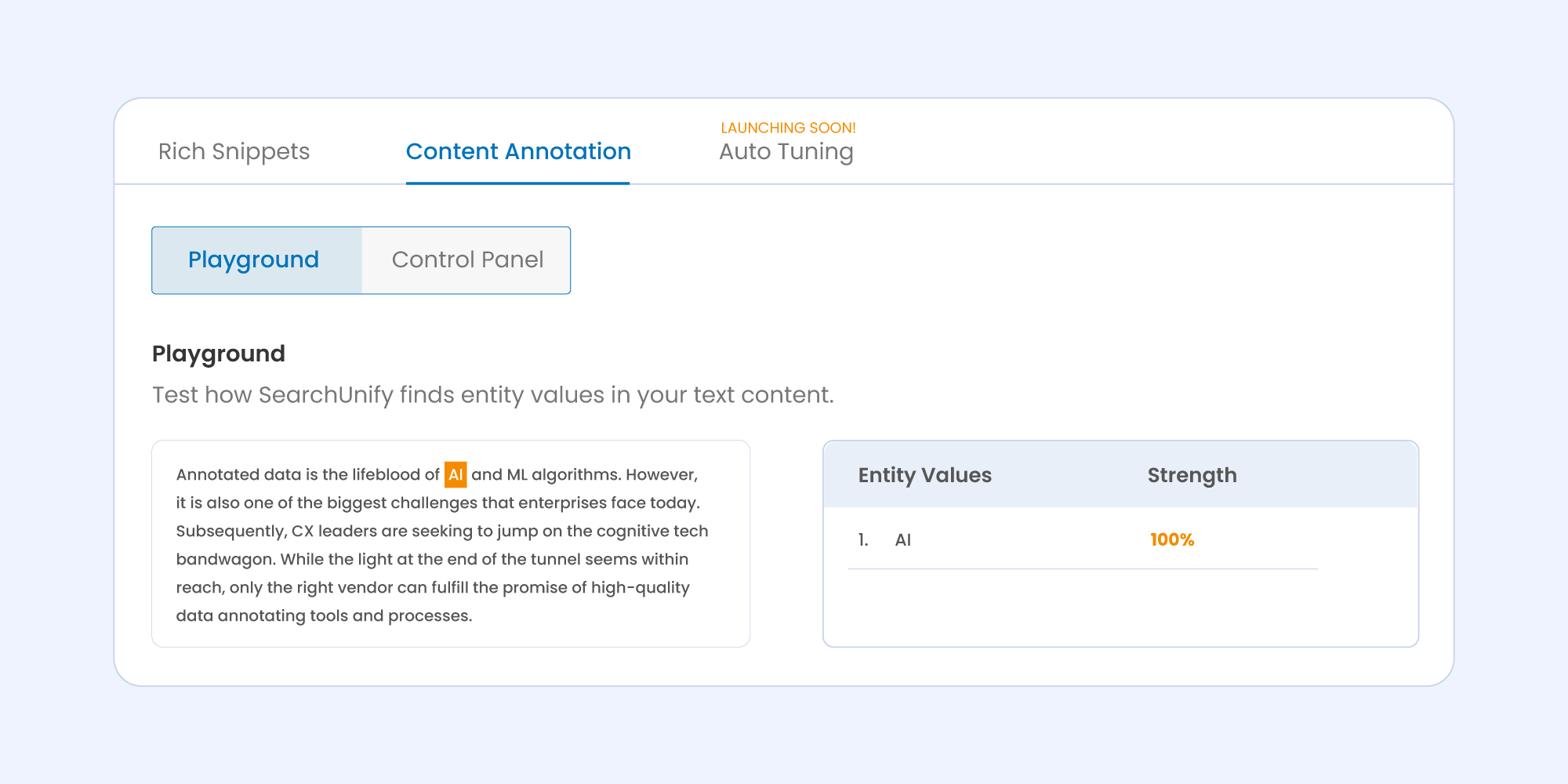
In case you wish to run the annotation again with more entities, simply click on Run Again. Doing so will take you back to where you started and enable you to repeat the process all over again with new entities, just like the illustration below:
What’s Coming in The Next Analytics Age for SearchUnify?
With Mamba ‘23, users got visibility into how SearchUnify’s ML algorithms predicted accurate outcomes without being explicitly programmed—but what if you could alter the ML program altogether to match your needs?
That is exactly what we aim to deliver with the next release—the ability to tweak ML systems and customize their very framework according to customer needs, thus further pushing it toward more precise results. Nifty, right?
For more insights into SearchUnify and its incredible features, request a demo now!














