
In the ever-evolving support landscape, the importance of personalized and context-aware customer interactions cannot be overstated. Large Language Models (LLMs) such as OpenAI™ ChatGPT and Anthropic’s Claude have donned the spotlight with their remarkable ability to generate human-like responses and perform a multitude of natural language processing (NLP) tasks.
Despite this, LLMs have their limitations that impede businesses from meeting the expectations of new-age customers. This is where the cutting-edge SearchUnifyFRAG™ (Fragmented Retrieval Augmented Generation) approach emerges as a game changer.
In this blog post, we will dig deeper into the SearchUnifyFRAG™ approach and how it helps maximize the potential of LLMs, thereby driving seamless support experiences.
But First, Let’s Know Where Large Language Models Fall Short:
As innovative as LLMs may be, they encounter several challenges:
- Limited Context: Imagine seeking assistance from an LLM for a complex customer query. More often than not, LLMs fall short of providing answers that are aligned with the unique business and user context. They tend to produce generic responses that lack the depth of a specific task or domain.
- Training on Potentially Outdated Data: LLMs are only as good as the data they are trained on. They are often trained on vast datasets that encompass a wide span of time. For example, GPT-4 does not have access to information beyond 2021. This affects the model’s ability to generate up-to-date responses, making it challenging for enterprises to keep up with the evolving customer needs.
- Limited Access Controls: A business may have different types of end users, each having unique needs and preferences. However, since LLMs do not take into account user access control, an organization struggles to provide personalized responses based on the user’s role or permissions.
- Hallucinations: While LLMs are well known for producing responses as ‘natural’ as human language, they are not always factually correct. As a result, a common challenge with these models is that they tend to hallucinate. For example, the LLM might suggest that the customer can return the product up to a year after purchase when the actual policy allows only a 30-day return window. This misinformation could lead to a rise in customer escalations, hence the increase in support costs.

Proven Ways to Redefine the Potential of Large Language Models
Addressing the inherent challenges that LLMs encounter is critical in elevating their performance and driving better outcomes. Two key strategies emerge as powerful tools in this pursuit:
1. Fine Tuning
It involves adapting the pre-trained LLM through extensive training on task or domain-specific datasets. The new dataset includes labeled examples relevant to the specific task. As a result, the model generates more accurate responses.
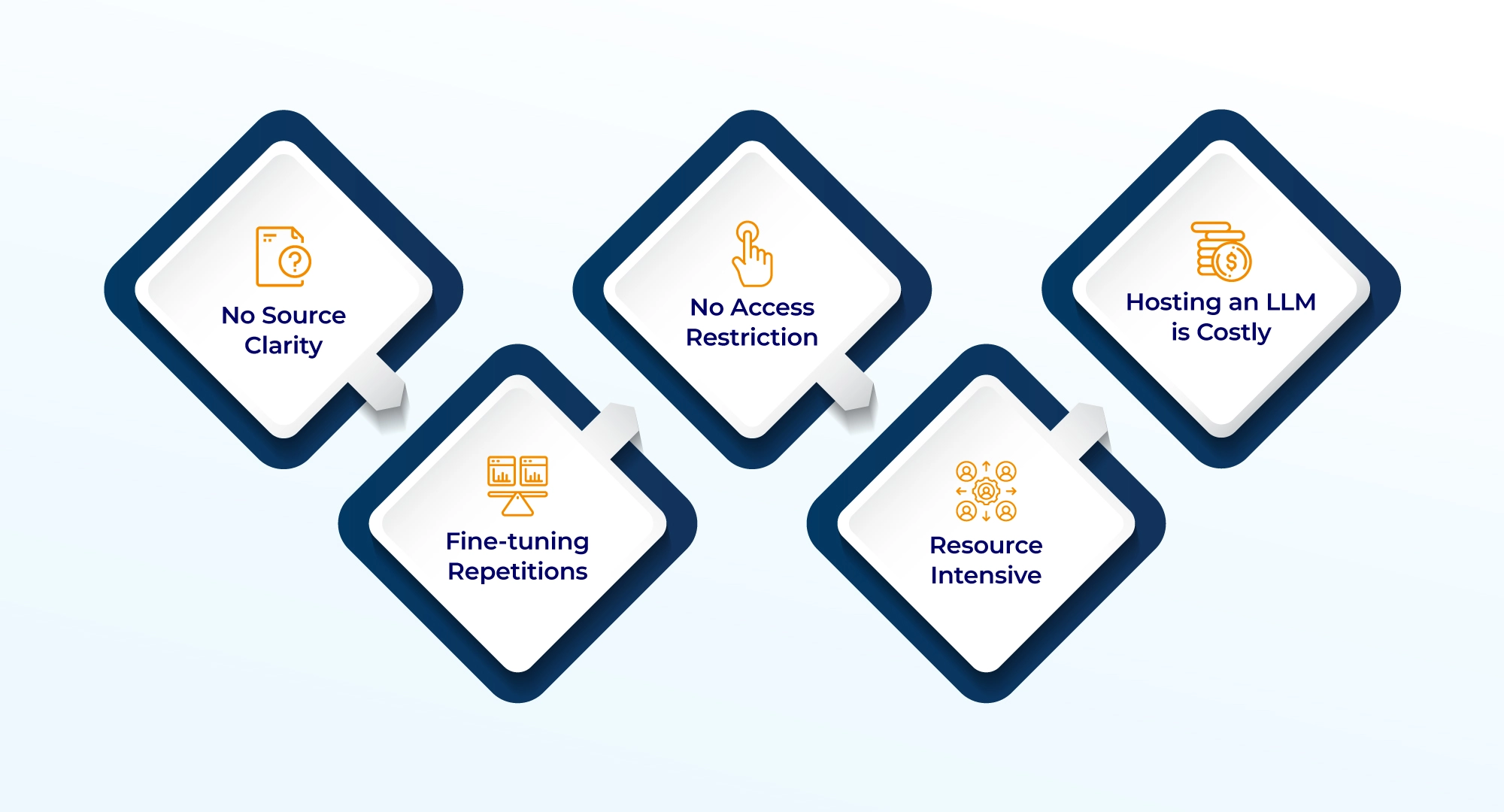
Downside of Fine-tuning
- No Source Clarity: Fine-tuning can sometimes obscure the source of information within an LLM’s responses. This lack of transparency can make it challenging to trace the origin of the generated content, leading to potential accuracy issues.
- Fine-Tuning Repetitions: Fine-tuned models may exhibit repetitive behavior, generating similar responses for slightly varied queries. This repetition can reduce the diversity and depth of the interactions, potentially frustrating users seeking nuanced information.
- No Access Restriction: Fine-tuned models may struggle with enforcing access restrictions on sensitive or confidential information. This limitation raises concerns about data privacy and security, as certain details might be divulged unintentionally.
- Resource Intensive: Training or quantizing the model on different parameters requires large datasets, heavy computing, specialized skills, and regular retraining to stay current.
- Expensive: Hosting and maintaining a fine-tuned LLM can be financially demanding. The associated infrastructure costs, combined with the need for regular updates and monitoring, can make fine-tuning a costly endeavor, especially for smaller businesses.
2. Context Building with Retrieval Augmented Generation (RAG)
Context is the key factor in achieving accurate and relevant responses. LLMs need to build and maintain context throughout the conversation to provide meaningful answers.
One of the most popular approaches that fuel context building among LLMs is: RAG (Retrieval-Augmented Generation). It boosts the reliability of these models by anchoring their responses in factual data sourced from a vector database. This not only guarantees the accuracy of the generated information but also offers users a reference point to validate the data. Moreover, by honing in on factual data related to specific domains, RAG enables LLMs to excel in tasks within particular domains, yielding outputs that are not only precise but also reliably aligned with the context.
Downside of Context Building with RAG
- Context Length Limitation: A context length is the number of tokens a model can process at once. For most LLMs, the context length limit for the prompt is limited to a few hundred tokens at most. For example, ChatGPT (GPT 3.5) context length is limited to 4096 tokens, i.e., 6 pages of English text (assuming 500 words per page).
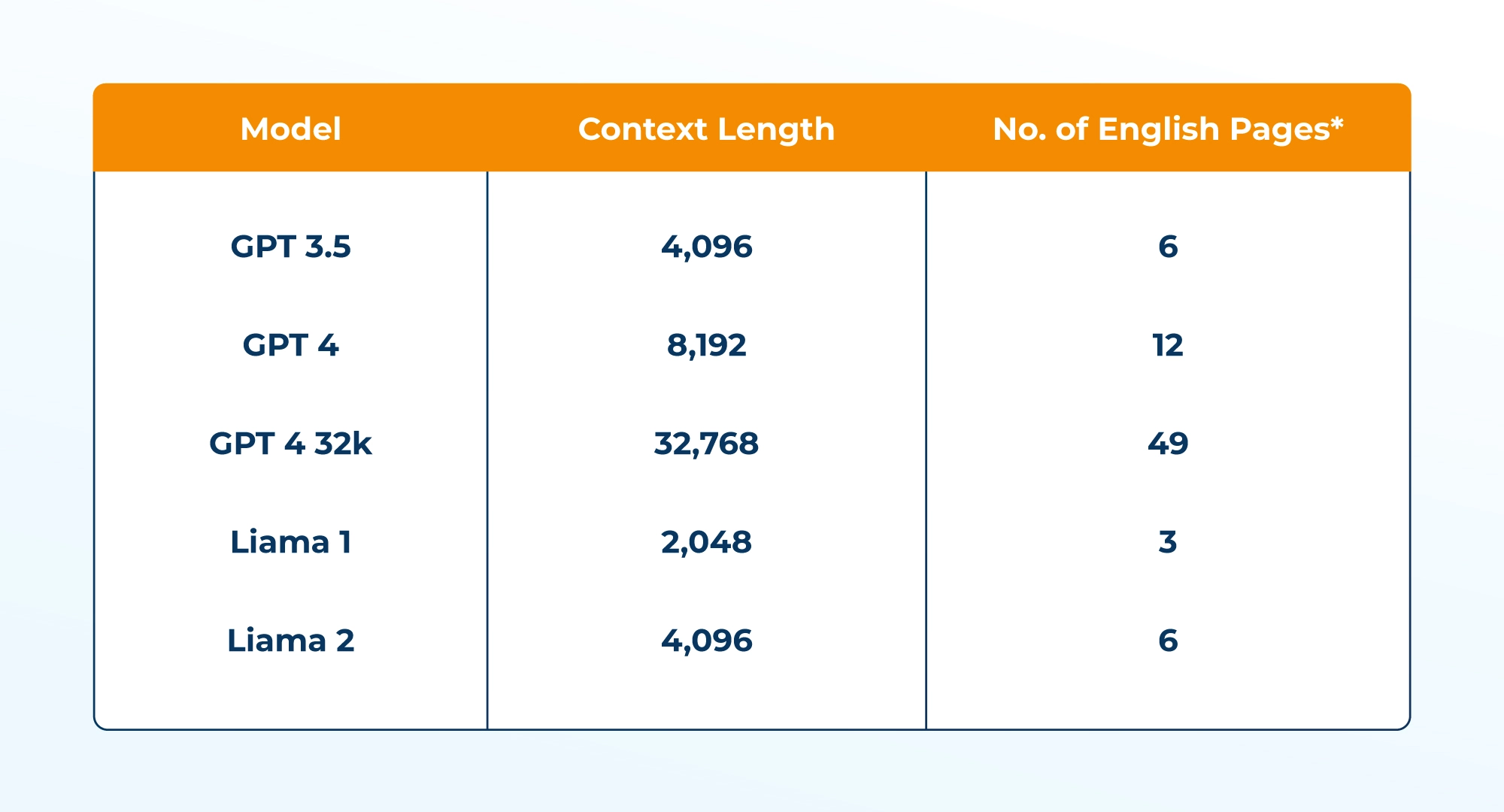
Here, the problem with RAG is if the combined length of the input sequence and the retrieved documents exceeds the set limit, the information will be truncated, therefore impacting the quality of the response.
- Limited Contextual Understanding: While the RAG approach aims to enhance contextual understanding, there can still be limitations in capturing nuanced or specific context. LLMs may struggle to grasp the subtle context, leading to inaccurate or incomplete responses.
- Dataset Bias: LLMs are trained on vast amounts of data, and if the training data is biased or contains skewed information, it can lead to biased responses. The RAG approach may inherit and amplify these biases, potentially resulting in skewed or unfair outputs.
- Information Retrieval Challenges: The retrieval layer in the RAG approach relies on accessing relevant information from a knowledge base. However, the accuracy and completeness of the knowledge base can impact the quality of retrieved information. Incomplete or outdated knowledge bases may lead to inaccurate or irrelevant responses.
Breaking Barriers with SearchUnifyFRAG™: A New Era for LLM Optimization
SearchUnifyFRAG™ (Federated Retrieval Augmented Generation) represents the revolutionary approach to optimizing LLMs. Leveraging the combination of three layers: Federation, Retrieval, and Augmented Generation, it enhances the model for more context-aware, personalized, and efficient response generation.
Let’s understand in detail:
- Federation Layer: It focuses on enhancing user input with context retrieved from a 360-degree view of the enterprise data. This helps the model generate responses that are not only relevant to the user but also incorporate context signals across customer journeys and enterprise touchpoints. By leveraging this contextual knowledge, SearchUnify’s LLM-integrated products are empowered to generate more accurate and relevant responses with factual content.
- Retrieval Layer: It plays a crucial role in accessing the most pertinent responses from a predefined set of data with methods such as keyword matching, semantic similarity, and advanced retrieval algorithms. This layer acts as a filter, ensuring that the generated responses are based on reliable and verified data, thus enhancing the reliability and accuracy of the LLM outputs.
- Augmented Generation Layer: It includes producing human-like responses or outputs based on the retrieved information or context. SearchUnify’s suite of products leverages techniques such as language modeling and neural networks to achieve this. By employing sophisticated algorithms and models, the Augmented Generation Layer ensures that the responses are not only contextually accurate but also natural and coherent in their delivery.
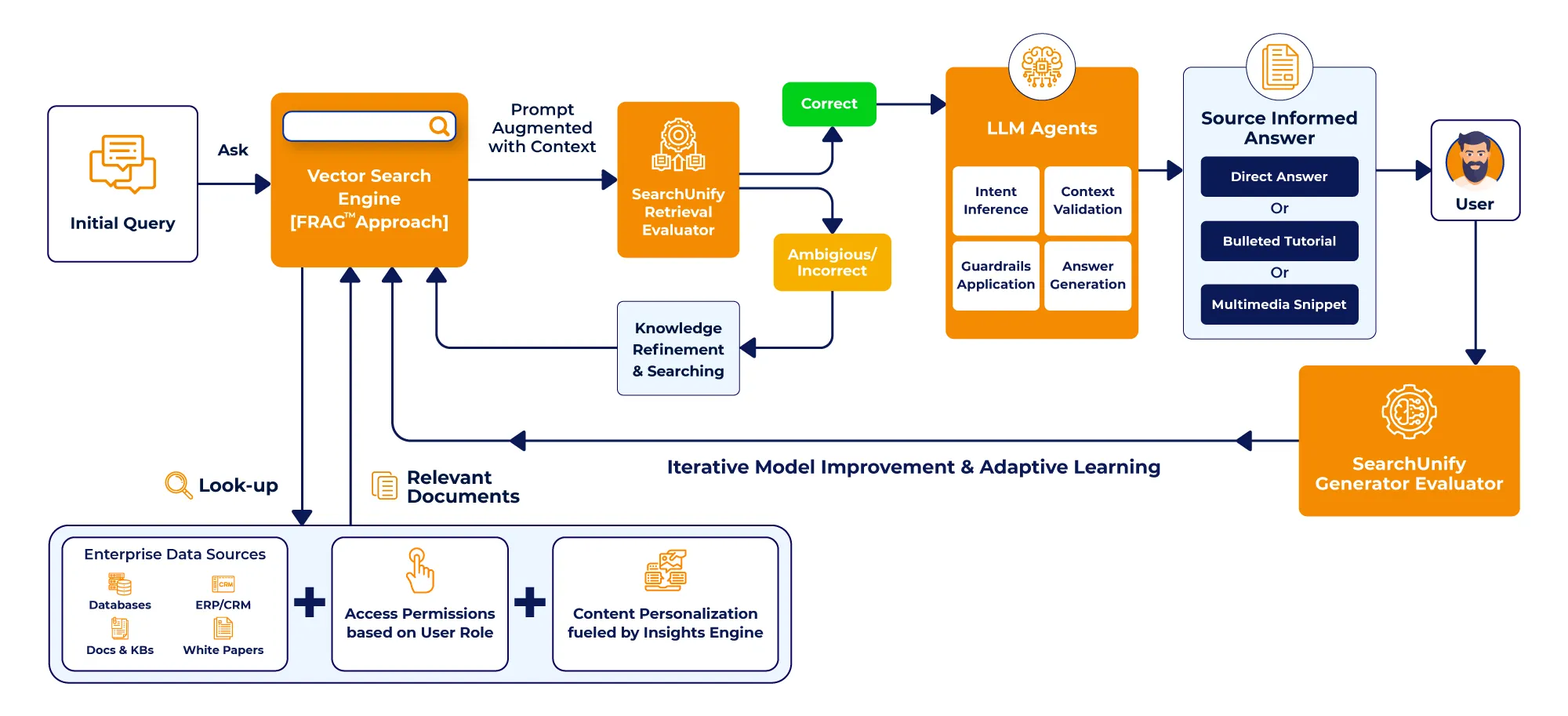
Here’s How SearchUnifyFRAG™ Works:
SearchUnifyFRAG™ when integrated with a vector search engine reduces the problem of hallucination among LLMs and empowers them to produce more precise responses. How you may ask?
It all starts with the customer’s initial query or prompt and running it through the local vector search engine powered by SearchUnifyFRAG™. This optimized prompt is then fed into the LLM. It then takes the input and generates relevant responses based on the information gathered from multiple repositories, including documentation, forum discussions, content in learning management systems, and more. The goal is to gather information closely related to the user’s query, ensuring a holistic approach to problem-solving.
That’s not all. SearchUnifyFRAG™ is also capable of integrating user access control layers. This means that the responses provided can be tailored based on the user’s role or permissions. For example, a business partner might see different documents than a customer.
To further enhance reliability, businesses can run another layer of a quick semantic search against the user’s query and validate the LLM-generated response. This additional step will help ensure that the generated response is contextually relevant, accurate, and aligns with the customer’s intent.
Ready to Harness the Full Potential of LLMs with SearchUnifyFRAG™
As the realm of LLMs continues to evolve, SearchUnifyFRAG™ is poised to play a pivotal role in enhancing their performance, ensuring accuracy, and delivering the next-level support experiences that set your business apart.
If you are interested in experiencing the power of SearchUnifyFRAG™ firsthand, request a live demo now.














