Imagine this: you’re in conversation with a friend, discussing Marvel Cinematic Universe movies. A slew of questions was being exchanged on the same topic. Wouldn’t it be weird if, after every question, your friend forgot what you were talking about? Well until recently, this was the scenario with search. Users had to retype their queries to make the context crystal clear.
But things are changing exponentially now.
Owing to the growing popularity of virtual assistants like Alexa and Siri, a new kind of philosophy for human-computer interaction has hit the ground running. Known as conversational search, it allows a user to utter a sentence into a device, and receive a comprehendible reply.
Conversational search is often used interchangeably with the word ‘contextual search’ which is defined as a search technology that takes into account the context of a query in addition to the intent of a user to fetch the most relevant results. It is the distillation of all things new-age customers value most – convenience, accessibility, and hyper-personalization.
This is possible by embedding the incoming queries. Wondering how? It’s time to find out!
What is Contextualized Query Embedding?
Since a machine only understands numbers, query embedding is the numerical representation of words to capture their meanings, the varied contexts they are used in, and their semantic relationship with each other, thereby equipping computers to understand them.
But how do we generate them? Or more importantly, how do they decipher the context? This is where the various techniques of query embedding come into the picture.
Common Approaches To Contextual Query Embedding
1. Word2Vec
One of the most popular natural language processing (NLP) techniques, word2Vec scans the complete corpus. Let’s understand it better with an example.
“Have a great day” and ‘Have a wonderful day.’ Although the sentences hardly differ, let’s grasp how a machine decodes it using the Word2Vec method.
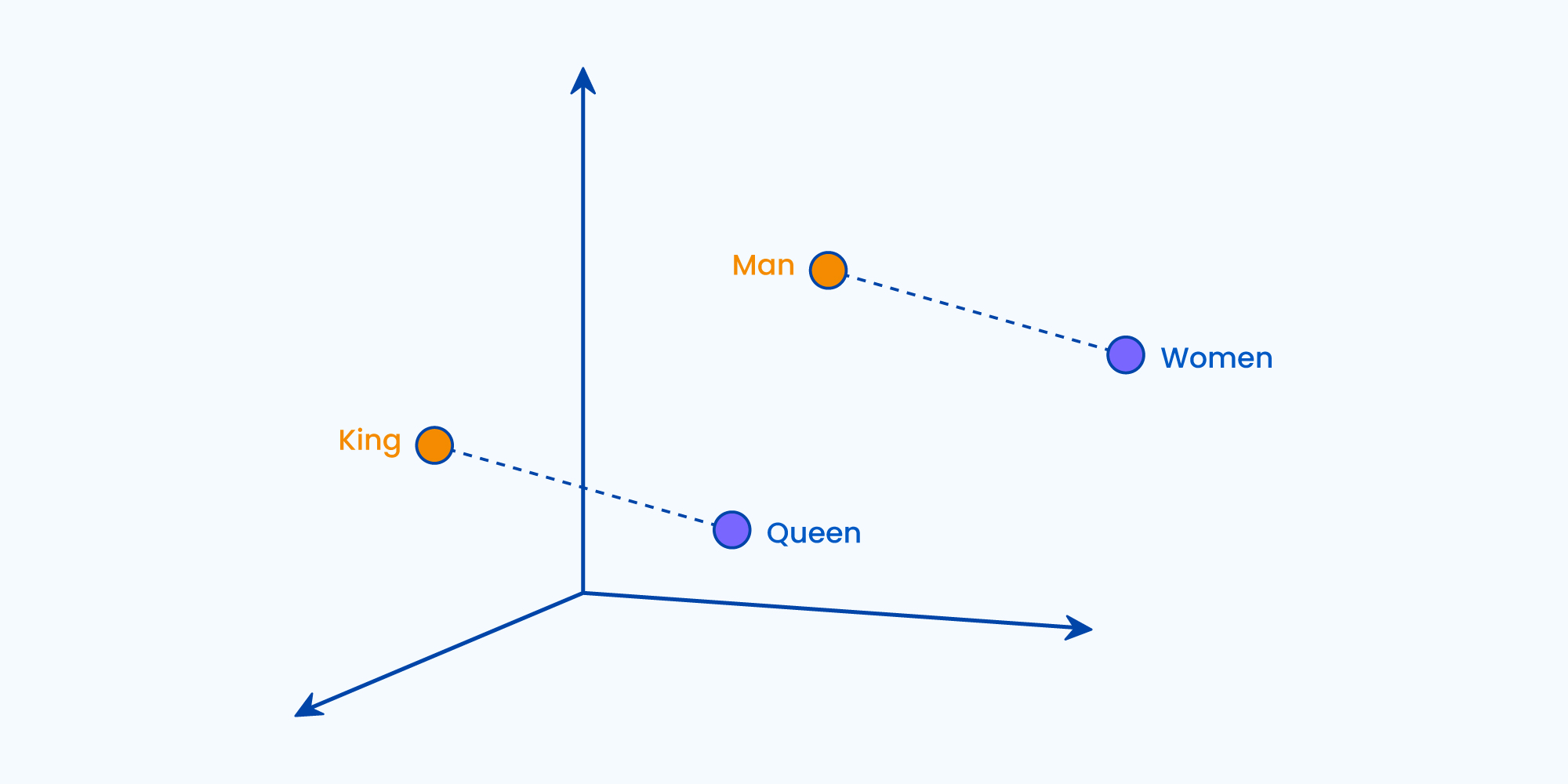
To begin with, the vector representation of a word may be a one-hot encoded vector where 1 is placed on the position the word exists and 0 is placed everywhere else. If we consider a vocabulary constituting these two sentences, it will cover the following words [Have, A, Great, Wonderful, Day]. The vector representation of the vocabulary would be:
Have = [1,0,0,0,0]; a = [0,1,0,0,0]; great = [0,0,1,0,0]; wonderful = [0,0,0,1,0]; day=[0,0,0,0,1]`
In any case, vectors can be created for different words in accordance with the given features. The words with similar vectors most likely have the same meaning or are used to convey the same sentiment. As evident from the word embedding image below, where similar words are closer thus hinting upon their semantic similarity.
There are two different model architectures that can be used to conduct Word2Vec, they are the Continuous Bag of Words (CBOW) model & the Skip-Gram model.
2. Sbert
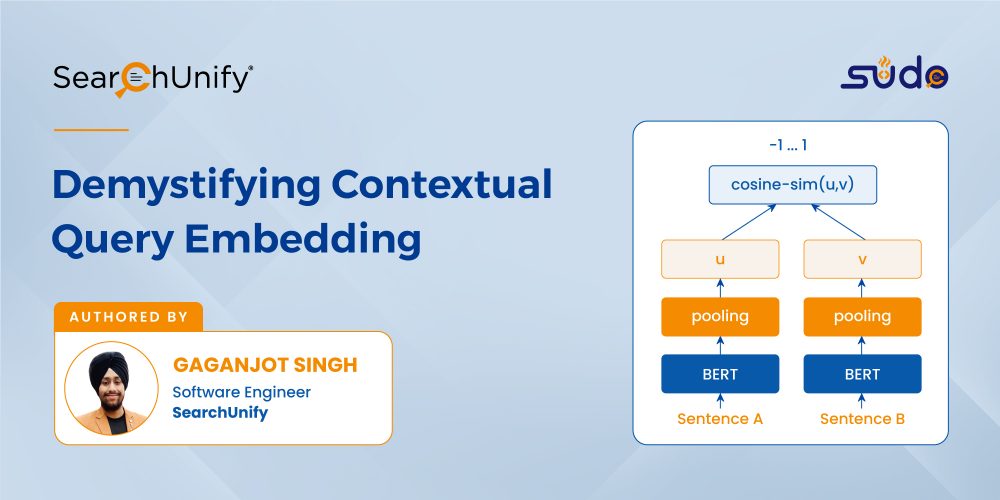
Sentence-BERT is a modification of the pre-trained BERT model that works on the python framework. It is designed to help computers understand the meaning of ambiguous language in text, sentence, and image embeddings. It deciphers the accurate context of a particular word using words that precede or succeed it.
This technique is also useful for inferring the intent behind search queries and enables users to train their own state-of-the-art question-answering system for more than 100 languages. But how does it outperform its predecessor BERT, which was once touted as the next big thing in contextualized query embedding? For starters, SBERT models are evaluated extensively and tuned to provide the highest possible speed. As a result, the time taken to find the most similar pair is mitigated from 65 hours to merely 5 seconds, all while retaining BERT’S accuracy. What’s not to love?
Differentiating SBERT From WORD2VEC
SBERT not only subdues its predecessor but is in fact a step ahead of all its opponents. Here’s how:
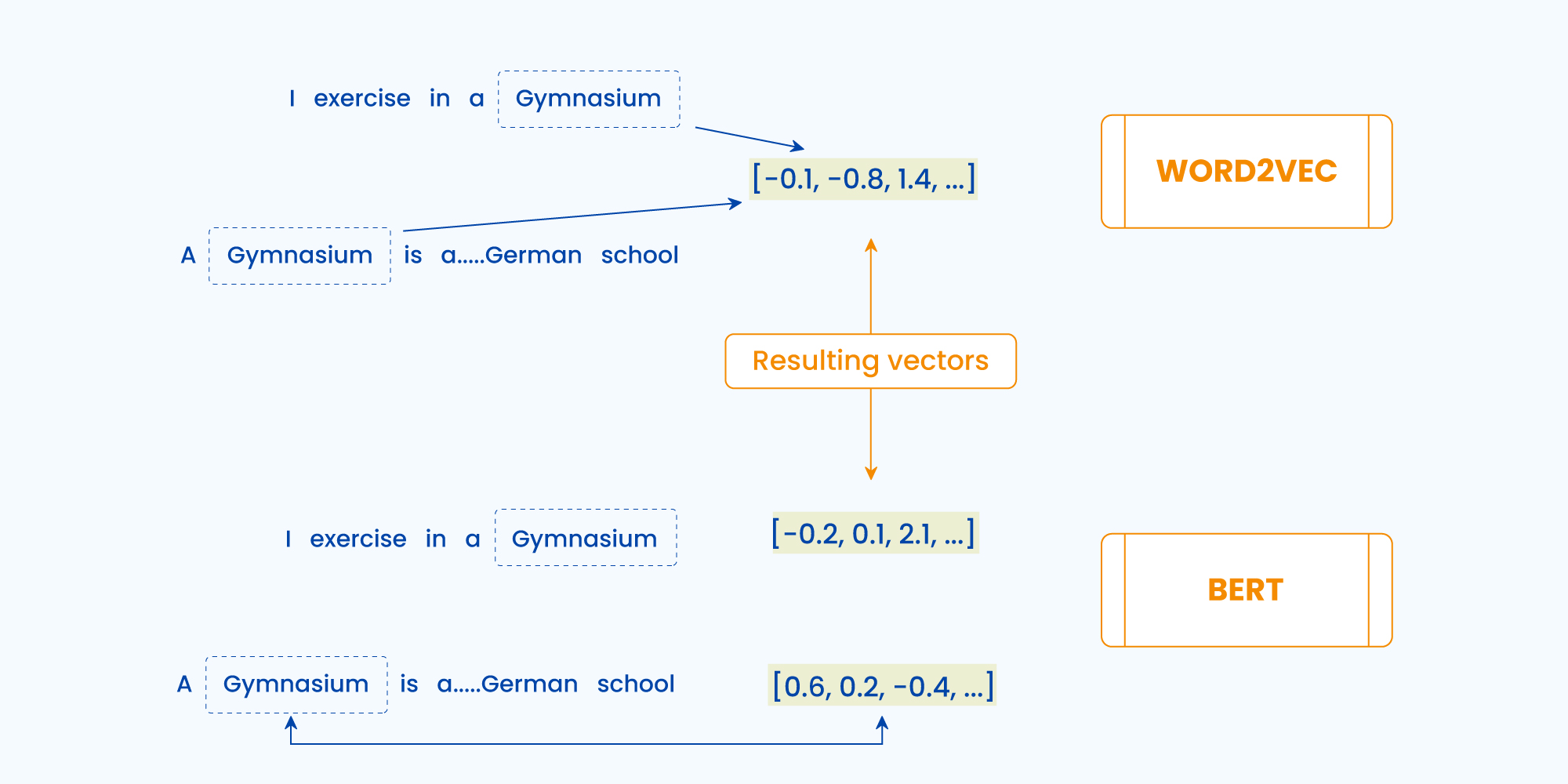
- Embeddings – S-Bert facilitates character-level, word-level, and sentence-level embeddings as opposed to word2vec or glove, where embeddings of each word are generated and then averaged out. However, in the process of separately embedding each word, the context is often lost.Word2Vec provides a single embedding vector for each word and is static in the application. This limits the capacity to capture different contexts of the same word (some popular examples are: ‘river bank ’and ‘bank deposit’).On the contrary, SBERT generates different output vectors for the same word when used in a different context.For example: “You are going there to teach, not play.” And “You are going there to play, not teach.” Both of these sentences will have the same representation in the vector space but they don’t mean the same. While S-Bert will first create word embeddings and then form the sentence embeddings with the help of a pooling layer within it. This layer will smartly average the word embeddings by rendering higher weightage to the contextual word when compared to a normal word(like – a, in, are, to, etc).

- Out of Vocabulary (OOV) – Word2Vec does not support OOV words and can not generate vectors for words that are beyond its vocabulary space. For instance, if a Word2Vec model was trained on a corpus of, say 1 billion unique words, then one vector for each word would lead to 1 billion word embeddings being generated. But if the model encounters an unknown word, no vector would be created.On the other hand, S-BERT supports OOV words. It provides representations on a subword level and incorporates a combination of both word-level and character-level embeddings. This enables the model to generate a vector for any arbitrary words and isn’t limited to the vocabulary SPACE. Thus, a BERT model will have a vocabulary space of only, say 50 million words, despite being trained on a corpus of, say 1 billion unique words.Next up, the image below is another fitting example to explain how SBERT outshines obsolete embedding techniques.
Too Difficult To Wrap Your Head Around Word Embeddings?
We got you covered. SearchUnify leverages SBERT to understand the ambiguous meanings of text by pre-training the ML model on a large dataset in an unsupervised manner.
If you wish to understand the nitty-gritty of how we deliver immaculate results in a jiffy using this widely-acclaimed method of query embedding, then request a demo today.















