
In a world where innovation reigns supreme, Large Language Models (LLMs) have emerged as a revolutionary force. Trained on a massive corpus of text data, they can generate human-like responses and perform various natural language processing (NLP) tasks, such as language translation, text summarization, and more.
But have you ever been curious about how they work? Well, the magic behind the incredible language capabilities of LLMs is–Transformers!
Transformers are artificial neural network designs that are used to fix the problem of transducing or transforming input sequences into output sequences. ChatGPT, developed by OpenAI, is a prime example of an LLM with transformers.
This blog post delves deeper into the concept of transformers and how their emergence has revolutionized the field of language modeling.
A Glimpse into History of Language Modeling Before the Age of Transformers
Before transformers, most NLP systems relied on traditional Bigram language models and Recurrent Neural Networks (RNNs). While each played a pivotal role in NLP, they presented significant challenges in capturing complex linguistic patterns and generating coherent text.
Let’s understand this in detail!
Bigram Language Model
A bigram language model is a type of statistical language model that considers pairs of adjacent words (bigram) in a text. By analyzing the frequency of these word pairs, the model predicts the probability of a word in a sequence based on the previous word.
Example sentence: “I like to code.”
Bigrams: (I, like), (like, to), (to, code)
Here the Bigram model would estimate the probability of encountering the word “like” after the word “I” and the probability of encountering “to” after “like.”
However, the problem with this type of model is that it struggles to capture broader linguistic patterns that span beyond adjacent word pairs. This leads to a lack of coherence and accuracy in the generated text. Additionally, the model may encounter data sparsity issues, especially when dealing with rare or unseen word combinations.
Recurrent Neural Networks (RNNs)
Recurrent neural networks (RNNs) are a type of artificial neural network specifically designed to process sequential data. They excel in capturing dependencies and patterns within sequences due to their unique recurrent connections that enable information to persist over time. This distinctive property makes them highly effective in a wide range of tasks such as language modeling, sentiment analysis, and language translation.
Let’s consider an English-to-French translation task.
Given an input sentence in English, such as “The cat is sitting on the mat,” an RNN processes each word sequentially, using its hidden state to generate the corresponding French translation “Le chat est assis sur le tapis.”
However, the challenge lies in their inability to handle long sequences due to computational constraints. In addition, they cannot be parallelized due to their sequential nature, which limits their scalability for large-scale datasets.
Enter Transformers: Overcoming Limitations in Language Modeling
Transformers have revolutionized the field of natural language processing by overcoming the challenges of traditional models. Developed in 2017, they were initially designed for translation tasks.
But unlike RNNs, transformers can interpret the sequential data by processing the total input at once. Moreover, they can be efficiently parallelized, which means, with the right hardware, you can train extremely large models, just like GPT-3.
But the main question is–what sets them apart from traditional language models? Let’s find out!
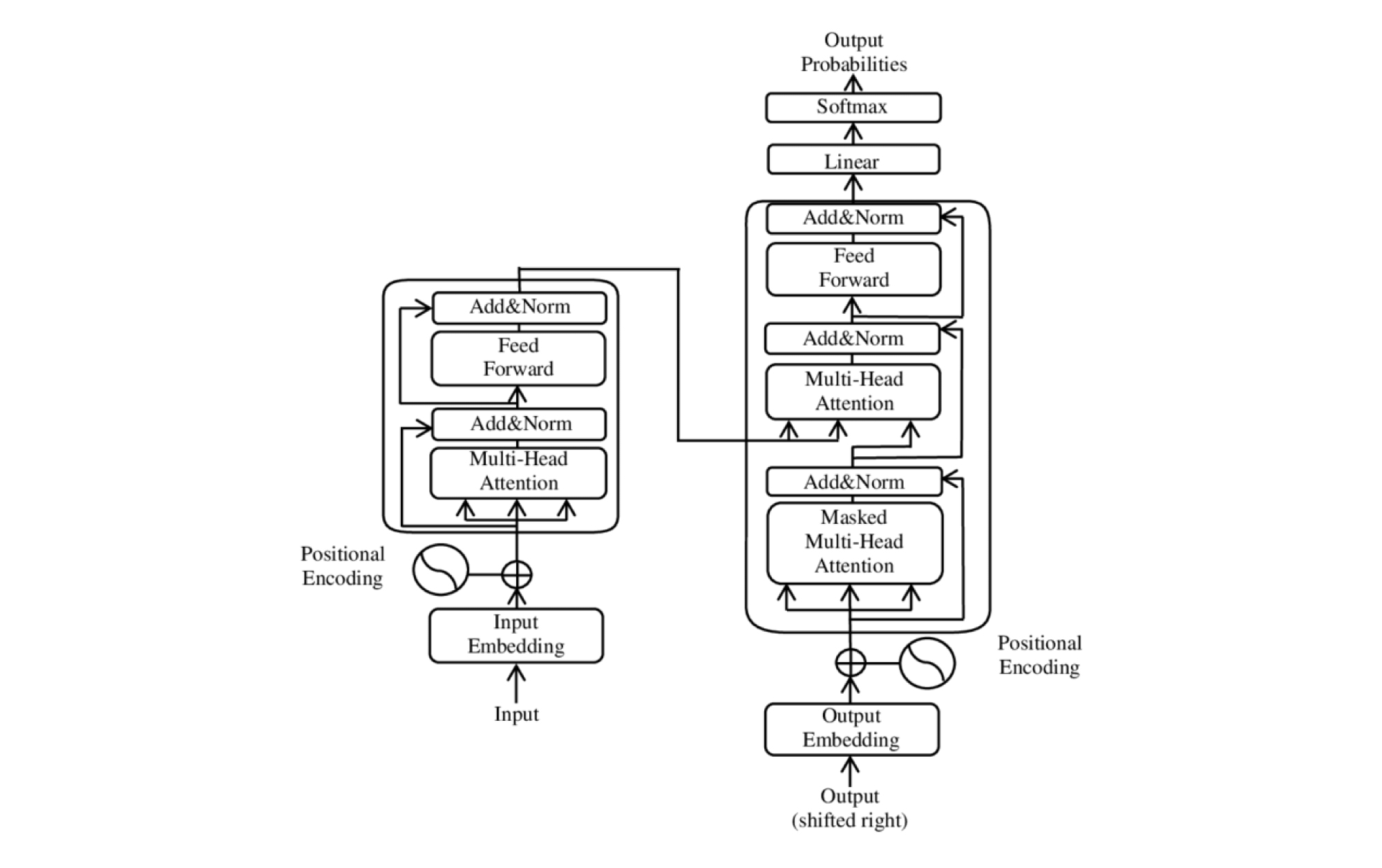
Positional Encoding
In natural language processing, the order of words plays a significant importance in determining the sentence’s meaning. But as we know, traditional language models fall short when it comes to understanding the order of inputs.
To address this challenge, transformers leverage positional encoding to assign unique numerical values or vectors to each word in the input sentence. These vectors capture positional information and are added to the word embeddings (vector representations of words) as additional input during the encoding process
Suppose you feed your network a sequence like:
[(“The”, 1), (“sun”, 2), (“sets”, 3), (“beautifully”, 4)]:
Using a positional encoding scheme, you can represent the positions as follows:
(“The”, 1) -> [0.841, 0.540, 0.000, 0.000]
(“sun”, 2) -> [0.000, 0.841, 0.540, 0.000]
(“sets”, 3) -> [0.000, 0.000, 0.841, 0.540]
(“beautifully”, 4) -> [0.000, 0.000, 0.000, 1.000]
In the above example, each word is assigned with a positional encoding vector, allowing the transformer model to better understand the sequence of words and generate accurate and semantically meaningful output.
Attention
One of the main reasons for the superior performance of transformers is the “attention mechanism.” It is a fundamental component of transformers that you must have heard about in machine learning these days. In fact, the paper that introduced transformers in 2017 was named—Attention is All You Need.
To understand how it works, let’s consider a language translation task from English to Spanish. The input sentence is “The neural network achieved state-of-the-art performance on the benchmark dataset.”
When generating each word in the output sentence, the model “looks at” every single word in the original English sentence. It creates a sort of heat map that shows where the model is “attending” when translating each word into Spanish.
For instance, when the model generates the word “red neuronal” (meaning “neural network” in Spanish), it attends heavily to the input words “neural” and “network.” This attention allows the model to capture the relationship between these words and accurately translate them. Similarly, when generating the word “conjunto de datos de referencia” (meaning “benchmark dataset” in Spanish), the model attends to the input words “benchmark” and “dataset,” ensuring a faithful translation.
The attention mechanism learns the association between words with the help of training provided on a large dataset of English-Spanish sentence pairs. By examining various examples, the model gains an understanding of word connections, grammar rules, and context.
Self-Attention
While vanilla attention helps align words across two sentences, more is needed when it comes to executing a number of language tasks. In simple words, the model must recognize patterns of word placement and replicate them when translating new phrases. This is where self-attention comes in.
It is a powerful mechanism that allows the model to understand words in relation to surrounding words, enabling the model to disambiguate meanings and capture rich semantic relationships.

For instance, consider the following sentences:
1. “The GPU is essential for deep learning computations.”
2. “I need to upgrade my GPU for better performance.”
Through self-attention, the model can attend to the word “GPU” in both sentences simultaneously. By doing so, it understands that “GPU” refers to the same hardware component in both sentences, allowing it to establish the semantic connection and recognize its importance in deep learning computations. The ability to attend to and comprehend relevant contextual information enhances the model’s understanding of technical terms and their significance in the given domain.
Ready to Explore the Marvel of Transformers?
Transformers have surpassed traditional approaches and achieved remarkable results in various natural language processing tasks. Request a free demo to witness their incredible ability to process vast amounts of data and capture complex patterns firsthand.
If you are eager to learn how SearchUnify is leveraging them for more relevant and contextual support, stay tuned for our upcoming blog post!















