
Imagine you’re a customer on a support platform. After a positive experience, you now have a similar query where you are seeking a unique, personalized solution. You’re looking for that perfect blend of familiarity and helpfulness. But how does the support platform discern what to recommend next?
Well, it’s scientific and it does have a secret sauce – vectors.
This cutting-edge tech, known as Vector Search, harnesses the power of vectors and enables support organizations to offer personalized recommendations that strike the ideal balance between what’s familiar and what’s new.
In our previous blog, we covered the applications of vectors and their potential impact on enterprise search. It set the stage for a deeper dive into SearchUnify’s technical implementation. So, how does this intriguing technology work in a mathematical way? Let’s find out!
What Are Vectors?
A vector is typically represented as an ordered list of numbers, known as components. For example, in a 2D vector, you might have (x, y); in a 3D vector, you’d have (x, y, z). Vectors are often denoted using variables with arrows, like →v.
Let’s understand better with a tabular representation:
Mathematical Representation of Vectors

In this table:
- “Vector Type” specifies whether it’s a 2D or 3D vector.
- “Representation” shows how vectors are typically written with their components.
- “Example” provides sample vectors →a and →b in 2D and 3D, respectively.
- “Variable” indicates that vectors are often represented using variables with arrows, like →a or →b.
Now that we’ve grasped the mathematical representation of vectors, let’s delve into the intriguing world of attributes and discover how they play a crucial role in distinguishing entities and shaping dimensionality.
The Role of Attributes in Entity Distinction and Dimensionality
Attributes play a crucial role in distinguishing two entities and can be viewed as vectors when converted into numeric form. These vectors, often referred to as feature vectors, help in quantifying the characteristics or properties of the entities. Here’s how attributes aid in distinguishing entities and how they can be seen as vectors:
-
Distinguishing Entities:
Attributes are pivotal in distinguishing two entities in the customer support industry. These attributes can be thought of as unique characteristics or properties that define an entity. For instance, if we are discussing customer support cases, attributes might include the type of issue, customer’s previous interactions, product version, language preference, and more. Each customer support case will possess specific attribute values that make it distinctive. For example, two cases might differ in terms of the reported issue, customer history, or preferred language, allowing for their differentiation. -
Attributes as Vectors:
When we convert these customer support attributes into a numeric format, we essentially create vectors where each dimension corresponds to an attribute. To illustrate this, consider two customer support cases:
Case A:- Issue Type: Technical
- Customer Interaction History: Extensive
- Product Version: 3.0
- Language Preference: English
- Priority Level: High
Case B:
- Issue Type: Billing
- Customer Interaction History: Limited
- Product Version: 2.5
- Language Preference: Spanish
- Priority Level: Medium
We can represent these customer support cases as vectors:

Each attribute corresponds to a dimension in the vector. For instance, “Issue Type” might be dimension 1, “Customer Interaction History” dimension 2, and so forth. The values within each dimension represent specific attribute values for that customer support case.
-
Embedding Size for More Detail
In the customer support industry, the dimensionality of these vectors (i.e., the number of attributes considered) significantly impacts the level of detail and accuracy in distinguishing support cases. This dimensionality is often referred to as “embedding size” or “dimensionality.”- Higher Dimensions
By increasing the number of attributes or dimensions, we can capture more intricate details about customer support cases. For instance, adding attributes like customer feedback sentiment, issue resolution time, customer satisfaction score, and product category can result in a higher-dimensional vector that provides a more comprehensive description of each support case. -
Improved Accuracy
With higher-dimensional vectors, our support systems can potentially distinguish support cases more accurately because they take into account a broader array of characteristics. This can lead to enhanced accuracy in various tasks, such as case categorization, prioritization, or similarity measurement.
Increasing the dimensionality of these vectors enables the capture of more detailed information. However, it’s essential to strike a balance because adding too many dimensions can also lead to increased computational complexity and the risk of overfitting the data.
- Higher Dimensions
- Term Frequency-Inverse Document Frequency (TF-IDF): TF-IDF assigns weights to terms based on their frequency in a document relative to their frequency in a corpus of documents. Each term becomes a dimension in a high-dimensional vector space, and each document is represented as a vector where each dimension corresponds to a term’s TF-IDF weight.
- Word2Vec: Word2Vec is a neural network-based model that learns word embeddings by predicting the context of a word within a large text corpus. It creates dense, fixed-size vectors for each word, such that words with similar contexts have similar vector representations.
- Doc2Vec: Doc2Vec extends Word2Vec to learn document embeddings. It associates a unique vector with each document in the corpus, capturing the semantic meaning of the document based on the words it contains.
- GloVe (Global Vectors for Word Representation): GloVe is a method that combines count-based and prediction-based techniques. It constructs a co-occurrence matrix of words in a corpus and then factorizes this matrix to obtain word embeddings. The resulting embeddings capture both global word relationships and local context information.
- BERT (Bidirectional Encoder Representations from Transformers): BERT is a pre-trained transformer-based model that can be fine-tuned for various NLP tasks. It generates contextual embeddings for words in a sentence by considering both left and right context, resulting in highly informative word representations.
- GPT (Generative Pre-trained Transformer): GPT is another transformer-based model but primarily used for generating text. It can also produce contextual embeddings for words and documents.
- Paragraph Vectors (PV): PV is a technique for learning document embeddings by predicting words in a document context. It combines elements of Word2Vec with a unique document vector that represents the overall content of the document.
-
ELMo (Embeddings from Language Models): ELMo generates context-sensitive word embeddings by using a bi-directional LSTM (Long Short-Term Memory) network. It produces multiple embeddings for each word, considering different layers of the LSTM, resulting in contextually rich representations.
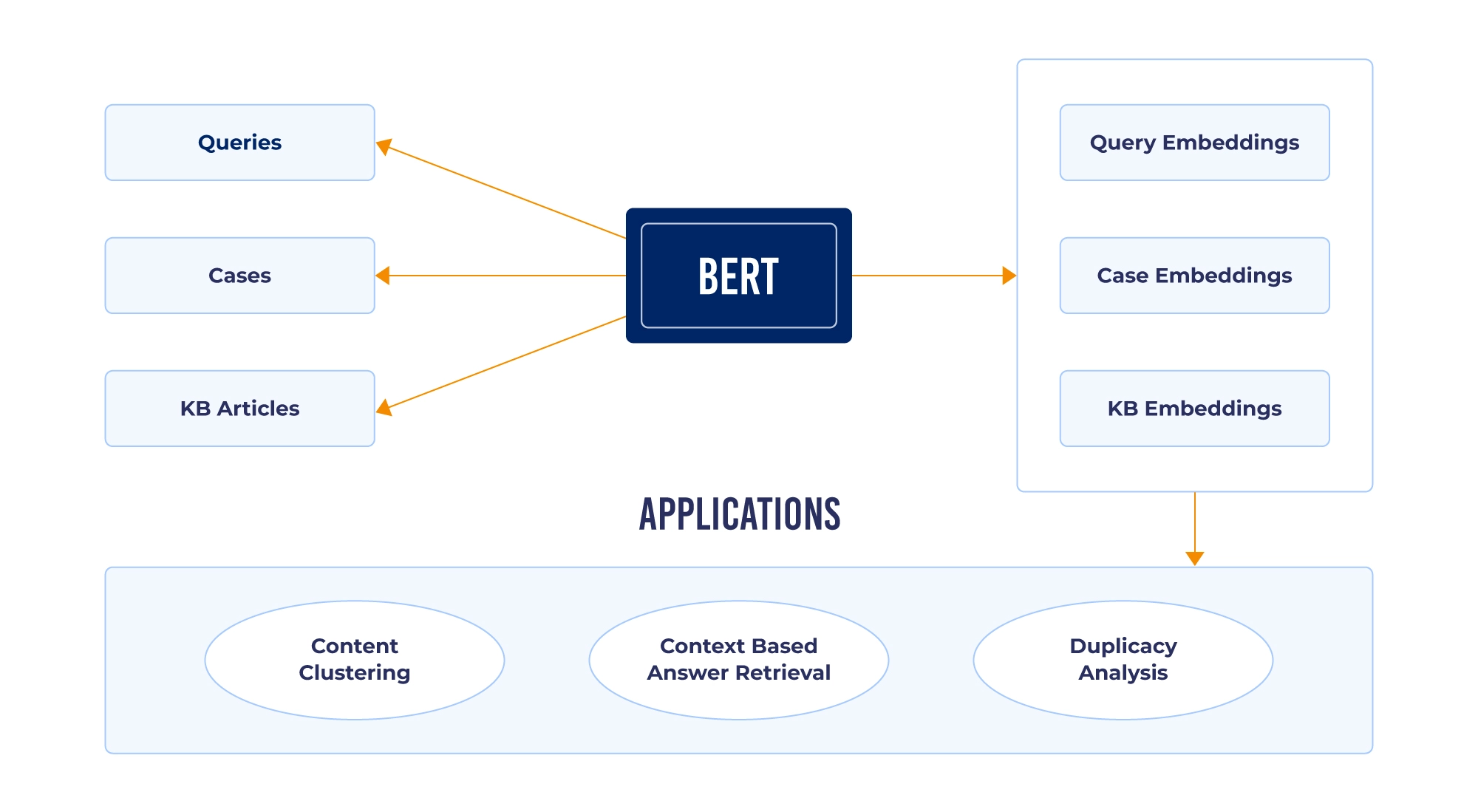
But what does SearchUnify bring to the table in terms of vector similarity search? Let’s find out!
Unveiling the Mechanics of Vector Search In SearchUnify
Vector representations, also known as word embeddings or document embeddings, are derived through various techniques. SearchUnify captures the semantic meaning and relationships between words or documents in a numerical vector format by using the following methods:
Count-based Methods:
Prediction-based Methods:
Transformer-based Models:
Elevate Your Support Experience with SearchUnify
SearchUnify enables support platforms to provide tailored solutions that strike the perfect balance between familiarity and helpfulness, using advanced vector-based techniques.
If you’re eager to witness how this cutting-edge technology can revolutionize your customer support experience, we invite you to request a demo today.















