
An IDC report suggested that the collective sum of the world’s data will grow to 175 zettabytes by 2025. Some estimates even suggest that 80-90% of this data is unstructured. “If one were able to store 175ZB onto BluRay discs, then you’d have a stack of discs that can get you to the moon 23 times,” says David Reinsel, senior vice president at IDC.
Unstructured data in business includes emails, presentations, data shared across chat, and other collaborative tools like web meetings, social media (posts, videos, etc.) This data is a treasure trove that contains answers to questions your employees and customers are asking.
But the problem is that companies aren’t able to tap it. No knowledge management initiative or cross-platform search seems to take the “information overload” bull by the horns. This is where semantic annotation can help. If you don’t know what it is, think about your favorite e-commerce site. Just like it tags different products under the right categories to make them easily discoverable, semantic annotation tags metadata to documents to improve their findability. If you want to understand semantic annotation to tap unstructured data of your company, this blog post is for you.
Why Semantic Annotation Matters
Rudimentary search engines or other keyword-based search solutions simply match the consistency or occurrences of the users’ keywords in existing documents. This results in a deeply upsetting and poor enterprise search experience. Additionally, these engines don’t possess the capability to self-learn from user behavior & roles to optimize results. In other words, they deliver a very flat and artificial experience. As a result, your employees spend the majority of their time scrambling for information.
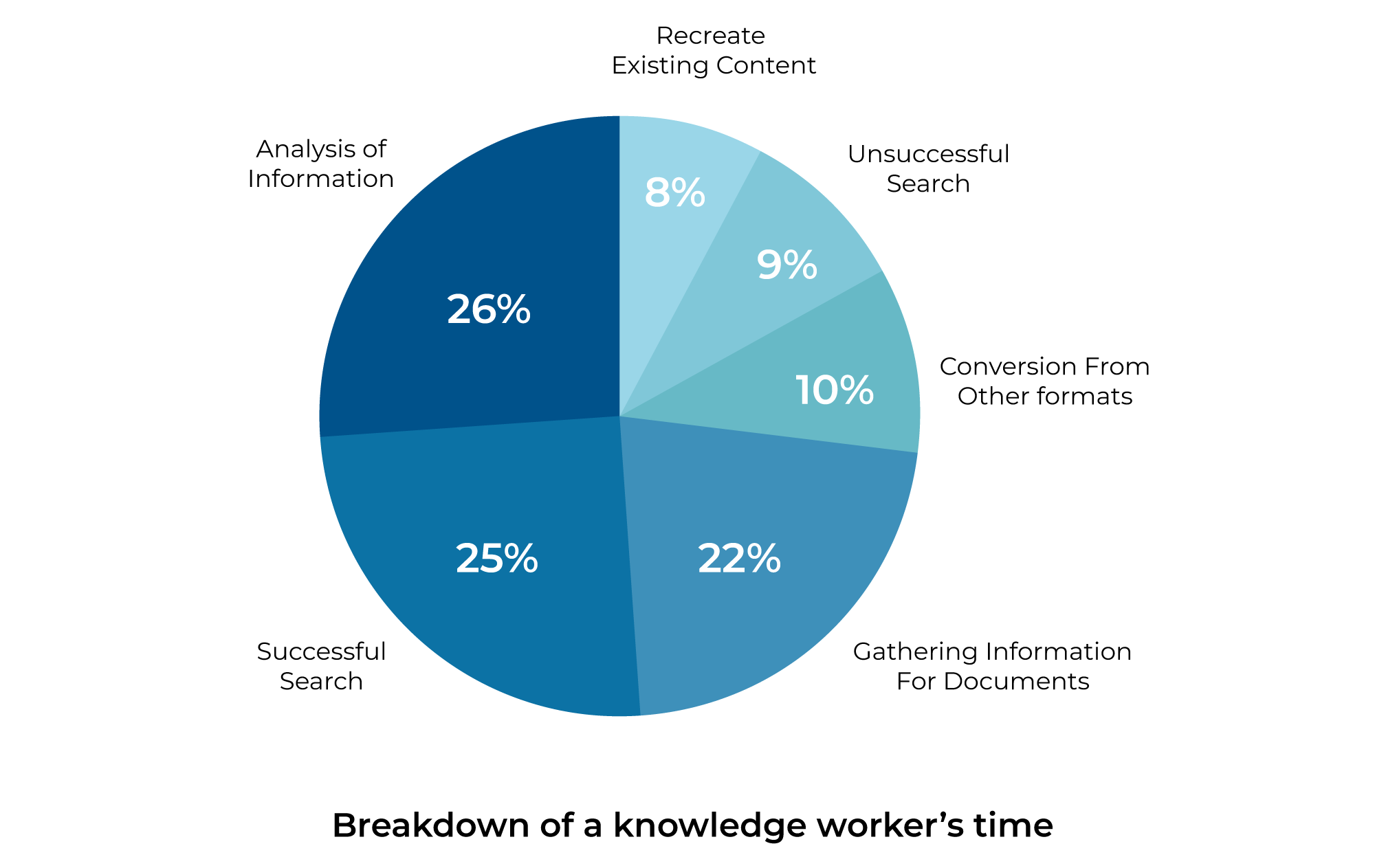
Furthermore, the fact that sometimes knowledge engineers and technical staff don’t follow guidelines, i.e if they have any in the first place, for developing knowledge (like writing proper file names) just adds to this iceberg of a problem. For instance, if there is a document in the knowledge repository labeled as ‘Project Proposal,’ it might be hard to find due to lack of additional details such as project name, version number, etc.
Generally, when users create content, they simply save it. Sometimes, they aren’t properly educated about metadata, and other times they’re simply too lazy. Research shows that even if users do tag documents, they are inconsistent, making it harder for the search engines to understand the relationship between words.
Last but not least of all the problems that make content findability a challenge–jargon. If users are searching for ‘bonus’ and the documents are labeled ‘variable performance-related pay,’ they probably won’t find it. Semantic annotations take care of all things above. They map the relations between words which helps in intent detection and entity extraction to surface the most relevant content.
How to Make Relevant Content More Findable
1. Metadata Management
Metadata is data about data. A search engine uses it to infer the intent of the searched query and subsequently return relevant results. Regulating the metadata and taxonomy of your organization serves as training for your search engine to perfect itself. Let’s say “Teams” is a product your company uses. You know it, your employees know it, but does the search engine?
It’s the taxonomy and well-defined metadata that’ll help your search engine understand better. It can be tough to tag hundreds of documents manually, that’s why you can rely on cognitive technology to do the heavy-lifting, and all you have to do is tune it. Know more about metadata management in this blog post.
2. Unsupervised Learning
Many cognitive solutions are powered by artificial intelligence and self-learning algorithms and automatically wrap context around the relationship between two pieces of information. They do so by integrating disparate data silos and unifying content (of different formats like video, docs, etc.) at the back end.
This helps deliver relevant results by identifying who the user is (based on role), where they have come from (analyzing the backlinks & past behavior), and what they need the information for.
3. Knowledge Graphs
The most effective way to build semantic annotation in your organization is through enterprise knowledge graphs. They are to an enterprise what maps were to people in the old world, only more.
A knowledge graph (KG) is a collection of interlinked information related to entities (people, events, places, etc.) that is easily understandable. It helps map semantic relations of words across various documents in your enterprise. This is a lengthy topic, but here’s a crisp blog post that will help you with the basics.
EndNote
Content findability is not just a search problem. You can optimize both, the content and search, for the best findability. Not sure where to start? Head to this on-demand webinar and learn from experts.
Watch this Insightful Panel Discussion Regarding Best Practices For Improving Content Findability
In this discussion, customer education, community, and customer success experts discussed key challenges and best practices for improving content findability and self-service success. Tune into it to get the latest insights.
















