
In this information-overloaded digital world, retrieving accurate and relevant information feels like finding a needle in a haystack. Retrieval-augmented generation (RAG) has addressed this challenge by retrieving relevant information from multiple repositories.
However, users’ expectations have evolved over time, and they expect more context-aware and nuanced information. This requires reasoning, profound contextual understanding, or multi-step thinking, where traditional RAG alone is not enough.
This is where Agentic RAG steps in to bridge this gap—a significant shift from merely searching for data to deeply comprehending and intelligently prioritising it.
Curious to explore this advanced approach to AI-powered information retrieval in depth? Look no further—this blog will explore Agentic RAG, its workings, and how it differs from traditional RAG.
Let’s dive in!

Source: Reddit (Limitation of traditional RAG)
The Limitations of Traditional RAG: Powerful, But Not Enough
RAG enhances the power of LLMs by extracting relevant information from external sources. LLMs rely on pre-trained data, and RAG helps them retrieve relevant and updated data from external sources, providing contextually accurate results.
Despite these capabilities, RAG has some limitations:
- Struggles with Information Prioritization: It often fails to prioritize relevant, high-quality content over general information, leaving users unsatisfied.
- Lacks the Ability to Reason: It retrieves the information but can’t explain why this happened or suggest a solution. It leaves decision-making to users only.
- Lacks Contextual Understanding: It fails to grasp the deeper context of the query, resulting in less relevant results.
- Less Effective with Multi-Step Tasks: It doesn’t provide a step-by-step response for a complex query because it can’t identify the root cause of the problem and cannot prioritize which step to take first.
What is Agentic RAG and How It Works
Agentic RAG is an advanced system that integrates an AI Agent into the RAG pipeline to overcome traditional RAG limitations. Now imagine what’s possible when the two work together. It will not just pull updated information but also make decisions on when to retrieve information, what to retrieve, how to integrate results, or when to ask for more explanation.
Unlike traditional RAG, Agentic RAG follows principles of agent-based systems such as planning, tool usage, and self-improvement. This enables it to become more adaptive, create intelligent workflows, and go beyond simple information retrieval.”
To transform your customer support with Agentic AI-powered Search solution
Let’s discussUnderstanding Agentic RAG Workflow
Agentic RAG answers by working through these four pillars — powered by two main components: the Intelligent Agent and the Dynamic Retrieval Pipeline.
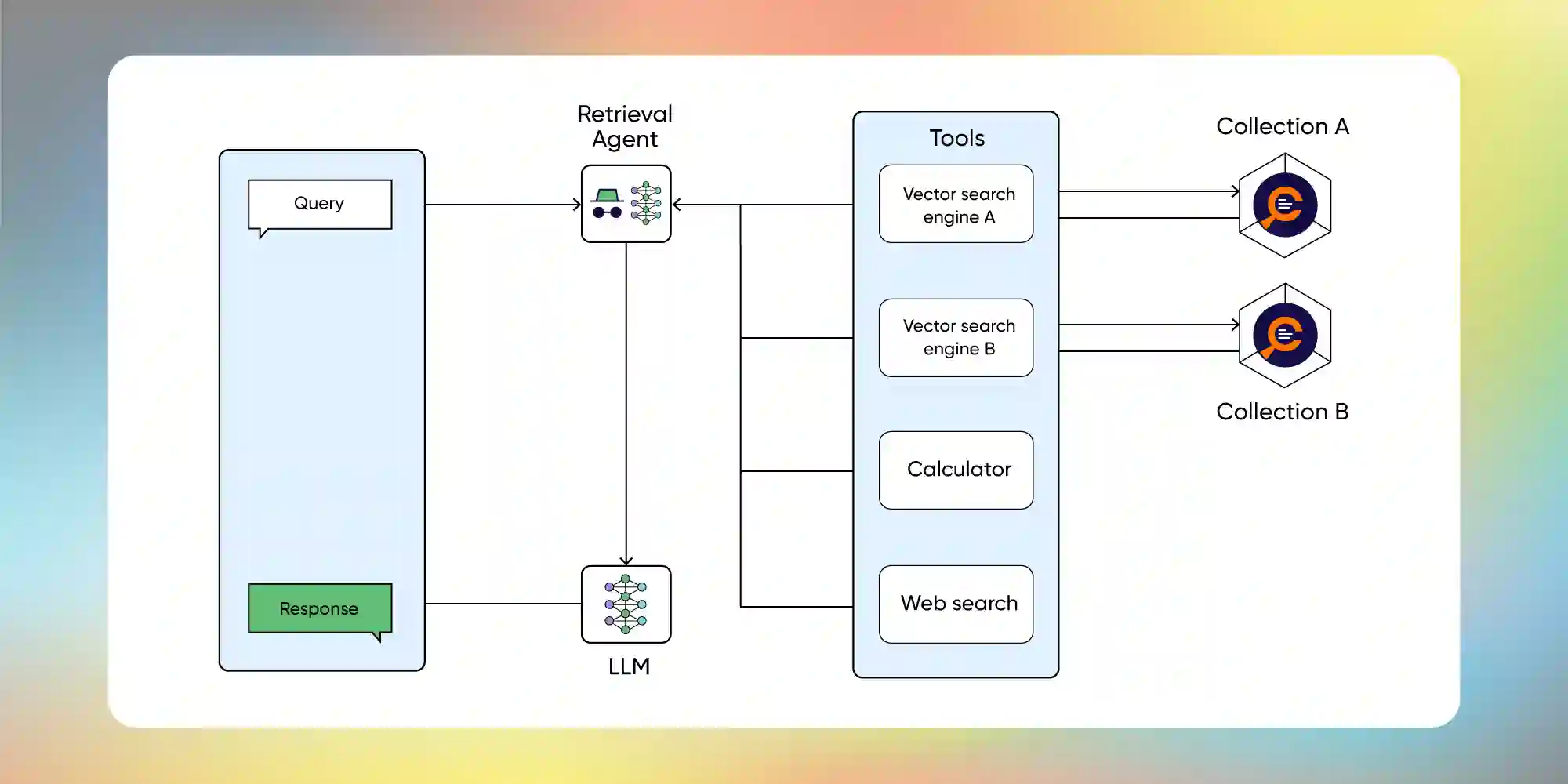
Intelligent Agent Understands and Decides
When the user searches for a query, it is combined with a prompt, and an AI Agent powered by LLMs examines the query to determine if it is vague or requires additional details. For instance, a user asked, “How do I set a strong password?”
An AI Agent expertly reads the question, grasps its context, and identifies what is needed to complete the task, acting as a proactive problem solver.
Now, the next question arises: which knowledge base should be chosen to get the relevant and accurate answer? And who will take this particular decision?
Do we need to write any manual code? The answer is no.
An AI Agent can route queries to the most relevant knowledge bases. It is pre-integrated with specific tools, such as Retriever tools (e.g., vector search). This setup gives us direct access to comprehensive information.
Suppose the AI Agent recognizes that DB1 (User guides/FAQs) and DB3 (system updates) are relevant to a query, and it must route the query to those particular knowledge bases. It will not mindlessly search all the knowledge bases, ensuring that the retrieved information is more accurate and contextually relevant to the query.
Dynamic Retrieval Pipeline Fetches Relevant Data
When an Agent decides on the knowledge base, it sends the query to those knowledge bases through a dynamic retrieval pipeline. This pipeline fetches the most up-to-date, relevant pieces of information related to password resetting from DB1 and DB3 (relevant knowledge bases).
If there are updates in the system policy about password rules, DB3 will provide the latest info. If there’s a step-by-step guide, DB1 will provide that.
Augmented Generation Builds a Helpful Answer
Agentic RAG doesn’t represent the information that it retrieves. It intelligently combines the pulled information and facts with its internal knowledge to generate a clear, contextual, and easy-to-understand answer like this:
“To set a strong password, use at least 12 characters, including numbers, upper case, lower case, and special symbols. You must avoid personal information like date of birth and change passwords every 3 months as per your company’s policy updated last month.”
Continuous Feedback Loop Improves Over Time
Agentic RAG continuously learns from the feedback it receives. For instance, a user asks a follow-up question or provides feedback, such as ‘It doesn’t work’ or ‘Could you explain more about password complexity rules?’
Based on feedback or interaction, Agentic RAG improves future knowledge base routing and answer quality. It becomes smarter with each interaction, much like a helpful human assistant who improves job performance through various learning experiences.
Agentic RAG vs. Traditional RAG: What Sets Them Apart?
| Dimension | Traditional RAG | Agentic RAG |
| Workflow | Follows a static, linear workflow where they retrieve once, generate once | Follows a flexible, iterative workflow where they perform multiple retrieve/generate steps, breakdown the problem or even change strategy if required based on reasoning |
| Decision Making & Adaptability | No self-checking if the answer is adequate; Always retrieves once and stops | The Agent can examine the intermediate results and decide if there is need to retrieve more information or utilize a different tool if the current context is limited |
| Tool Use & Data Sources | Typically connected to a single vector DB or document store | Connected to multiple databases and tools, with the ability to intelligently select the most relevant source based on the query |
| Self-reflection & Accuracy | No in-built feedback or self-verification loop | Incorporate self-reflection and feedback loops. Agents can reflect on drafted responses and verify it. If there is any gap, it refines queries, and re-fetch context for high accuracy and relevancy |
| Scalability & Complexity | Simple architecture, but limited scope and flexibility | More scalable — handling a wider range of complex queries and data sources |
| Multimodality | Mostly limited to text-based retrieval and generation | Can handle text, images, audio, and more using multimodal tools and models |
Transforming Enterprise Search into Answer-Driven Experiences with Agentic RAG
Traditional RAG set the stage for intelligent retrieval, but its static, one-shot workflow falls short as enterprise queries demand more context-aware, accurate answers—not just document links.
At SearchUnify, we’ve integrated Agentic RAG capabilities into our AI-powered enterprise search solution to transform search into dynamic, answer-first experiences. Whether it’s resolving support tickets faster, improving self-service success, or scaling knowledge discovery, Agentic RAG empowers enterprises to go beyond “search results” and deliver tangible outcomes.
It’s not just about finding information anymore—it’s about solving problems with intelligence, context, and precision.













